Thursday, December 18, 2008
Wednesday, September 10, 2008
Friday, August 29, 2008
Restoring Master and MSDB database in SQL Server
I don't need to mention the significance of Disaster Recovery (DR) plan for System and User Databases in SQL Server. I do test DR plan for User Database very often, but System Database generally I skip. In this post, I want to explain the DR plan and DR Plan testing for System databases. System database restoration is not as similar as User Database restoration. There are broadly three scenario where system database (Master and MSDB ) needs to be restored
(a) Master or MSDB to be restored from a earlier backup to undo the changes
(b) The Server machine crashed and sql server have been reinstalled with fresh copy.
(c) SQL Server is not starting because Master database corrupted
This scenario is well covered in this article
Proposed Backup Plan for System Databases
(a) Full Backup Daily
(b) If any major changes done like replication configuration or creation of Jobs take a backup of system databases after the configuration
You can either go for Hot Backup of Cold Backup of System databases. Hot backup is nothing but taking backup of system databases using BACKUP DATABASE T-SQL Command and you have to restore that backup using RESTORE DATABASE command. Hot backup is an online activity. Cold backup is stopping the SQL Server Engine , Copy MDF and LDF physical files to a backup location and Restart the service. Cold backup requires downtime and generally it is not the case in Production servers.
Scenario 1 : Restore Master & MSDB databases form the Backup file
I have full backup of Master and MSDB. My Master and MSDN databases got corrupted or i did some major changes and i want to rollback. Since i have backup i can restore the system database from the backup.
High level Steps
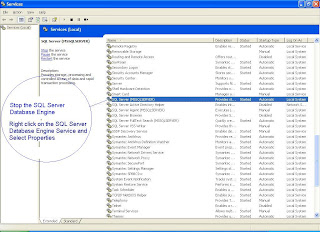
(a) Stop and Start the SQL Server Database Engine in Singe User Mode
(b) Restore the Master Database from SQLCMD prompt
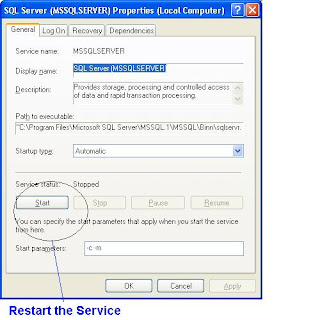
(c) Start the SQL Server Database Engine
(d) Restore MSDB Database
Windows Start -- Run – Services.MSC --- Enter
You will get this window
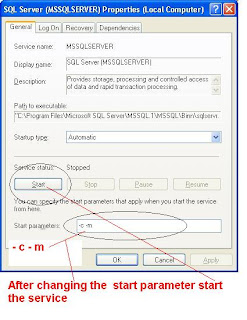
Restore the Master Database from Command Prompt
Windows --- Start --- Run --- CMD --- Enter
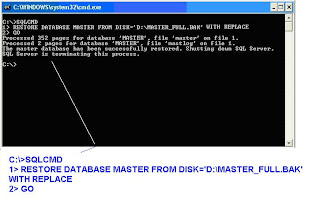
-- If the Screen is not readable this is the command and the result
C:\>SQLCMD
1> RESTORE DATABASE MASTER FROM DISK='D:\MASTER_FULL.BAK' WITH REPLACE
2> GO
Processed 352 pages for database 'MASTER', file 'master' on file 1.
Processed 2 pages for database 'MASTER', file 'mastlog' on file 1.
The master database has been successfully restored. Shutting down SQL Server.
SQL Server is terminating this process.
C:\>
The message says that you have successfully restored Master database.
Note : You have to restart the Database Engine Now
Restore MSDB Database from Management Studio
RESTORE DATABASE MSDB FROM DISK='D:\MSDB_FULL.BAK' WITH REPLACE
Scenario 2 : Server Crashes – Reinstalled SQL Server Instance
In this scenario, the important point is , you must build the new installation to the same build from where the backup was taken. You have to have same OS Version Edition, Service pack ,Patches and You also must have SQL Server Version , Edition , Service Pack and Patches as the Earlier server from where the backup was taken. Once you build your server to the same configuration the process is same as mentioned in Scenario 1
(a) Master or MSDB to be restored from a earlier backup to undo the changes
(b) The Server machine crashed and sql server have been reinstalled with fresh copy.
(c) SQL Server is not starting because Master database corrupted
This scenario is well covered in this article
Proposed Backup Plan for System Databases
(a) Full Backup Daily
(b) If any major changes done like replication configuration or creation of Jobs take a backup of system databases after the configuration
You can either go for Hot Backup of Cold Backup of System databases. Hot backup is nothing but taking backup of system databases using BACKUP DATABASE T-SQL Command and you have to restore that backup using RESTORE DATABASE command. Hot backup is an online activity. Cold backup is stopping the SQL Server Engine , Copy MDF and LDF physical files to a backup location and Restart the service. Cold backup requires downtime and generally it is not the case in Production servers.
Scenario 1 : Restore Master & MSDB databases form the Backup file
I have full backup of Master and MSDB. My Master and MSDN databases got corrupted or i did some major changes and i want to rollback. Since i have backup i can restore the system database from the backup.
High level Steps
(a) Stop and Start the SQL Server Database Engine in Singe User Mode
(b) Restore the Master Database from SQLCMD prompt
(c) Start the SQL Server Database Engine
(d) Restore MSDB Database
Windows Start -- Run – Services.MSC --- Enter
You will get this window


Restore the Master Database from Command Prompt
Windows --- Start --- Run --- CMD --- Enter

-- If the Screen is not readable this is the command and the result
C:\>SQLCMD
1> RESTORE DATABASE MASTER FROM DISK='D:\MASTER_FULL.BAK' WITH REPLACE
2> GO
Processed 352 pages for database 'MASTER', file 'master' on file 1.
Processed 2 pages for database 'MASTER', file 'mastlog' on file 1.
The master database has been successfully restored. Shutting down SQL Server.
SQL Server is terminating this process.
C:\>
The message says that you have successfully restored Master database.
Note : You have to restart the Database Engine Now

Restore MSDB Database from Management Studio
RESTORE DATABASE MSDB FROM DISK='D:\MSDB_FULL.BAK' WITH REPLACE
Scenario 2 : Server Crashes – Reinstalled SQL Server Instance
In this scenario, the important point is , you must build the new installation to the same build from where the backup was taken. You have to have same OS Version Edition, Service pack ,Patches and You also must have SQL Server Version , Edition , Service Pack and Patches as the Earlier server from where the backup was taken. Once you build your server to the same configuration the process is same as mentioned in Scenario 1
Thursday, August 28, 2008
Configuring Linked Server from SQL Server to MySQL
Recently I got a project in which there was a Migration Task to be done from MYSql to SQL Server. Prior to this I never worked in MySQL and I thought it would be just simple as creating LinkedServer to mySQL and pull the data to SQL Server from SQL Server itself. So I decided to create linked server from SQL Server to My SQL and pull the data using OPENQuery Function. I tried to configure linked server in SQL Server and then realized that it is not simple as that. I had to lot of steps like download driver, install it , configure the provider etc. As usual I searched in net and found a thread which neatly mentioned the steps ( SQLServerCentral.com). This thread really solved my problem in hours. Of course the thread was good enough for an expert (indirect way of saying that am an expert ), but for a newbie it may be bit confusing. So I thought to make a comprehensive document which has all the step by step screen shots so that the process will be easier. Having said that, I am not taking any credit for this document, the whole credit goes to Jim Dillon who posted his solution in the above mentioned site.
Tested Environment :
Operating System : Windows XP, Windows 2000, Windows 2003
SQL Server : SQL Server 2005, (Note : I have not tested SQL Server 2000 but I feel it should work)
MySQL : MySQL Server 5.0
MySQL ODBC : ODBC 3.51
High level Steps
• Download and Install ODBC Driver from MYSQL Site
• Create ODBC DSN
• Create Linked Server in SQL Server
• Configure Provider
• Create linked server
• Enable OpenQuery in SQL Server instance
• Create Openquery script
Step 1 : Download MySQL ODBC Connector
Download MySQL Connector/ODBC 3.51 from : http://dev.mysql.com/downloads/connector/odbc/3.51.html
Download the ODBC connector for your Operating System. I have windows xp , so I will download Windows MSI installer (x86)
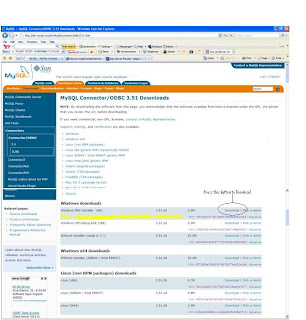
Step 2 : Install ODBC connector
Double click the downloaded file
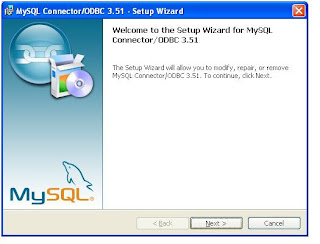
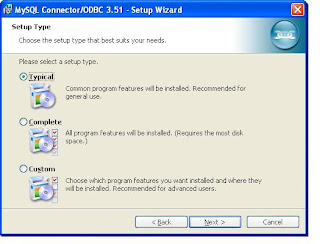
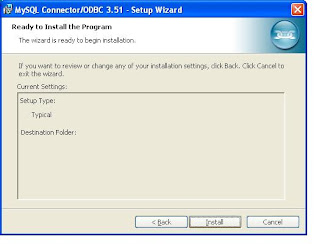
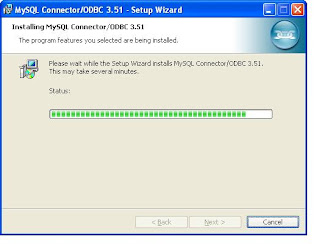
At last screen you will get a Finish button and click that. Now You have installed ODBC connector for MySQL.
Step 3 : Create System DSN for MYSql ODBC Driver
Windows Start --- >> Run --- >> odbcad32
Or
Windows Start --- >> Control Panel ->Performance and Maintenance (in XP) --- >> Administrative Tools -> Data Sources (ODBC)
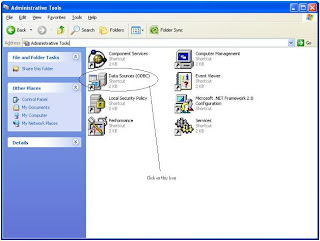
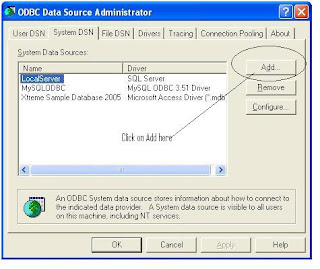
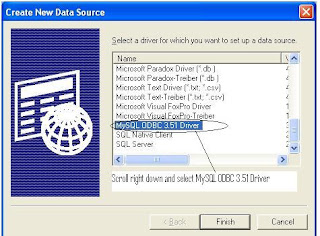
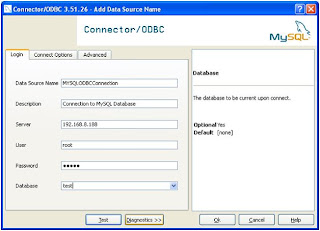
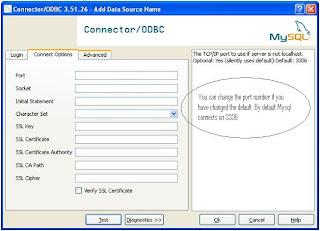
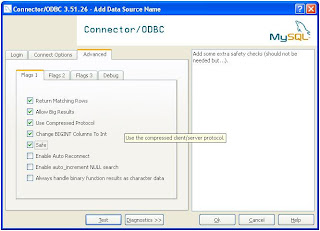
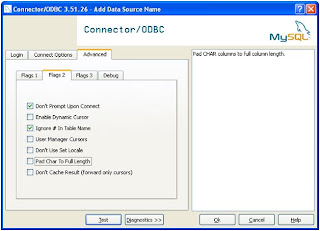
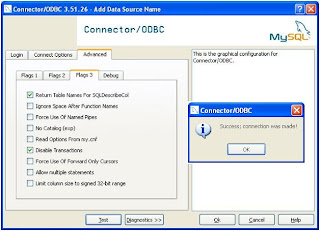
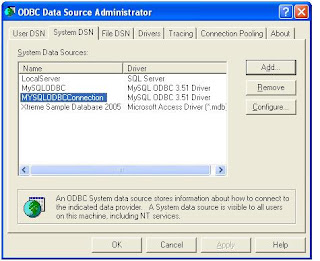
Step 3 : Create Linked Server in SQL Server 2005.
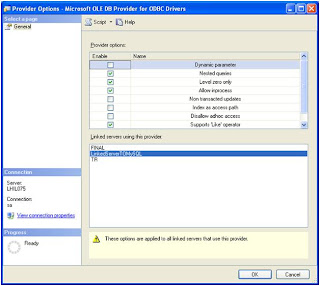
Change the properties of the Provider
Select the properties as shown in the screens
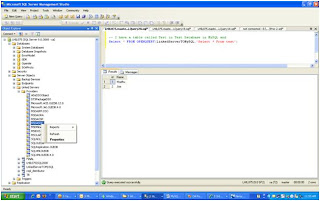
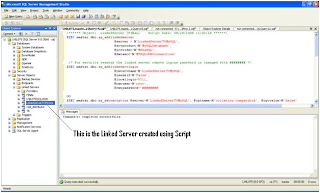
--======================================================================================================
Script to Create Linked Server
It is always better to create linked server using Script than GUI. You have more control and script of course is more readable. I am not giving the screen shot for this steps. Copy paste the script to a query analyzer change DSN Name, Username, Password and run.
--======================================================================================================
/****** Object: LinkedServer [LinkedServerTOMySQL] Script Date: 08/28/2008 11:40:28 ******/
EXEC master.dbo.sp_addlinkedserver
@server = N'LinkedServerTOMySQL',
@srvproduct=N'MySQLDatabase',
@provider=N'MSDASQL',
@datasrc=N'MYSQLODBCConnection'
Parameter Explanation
@server = N'LinkedServerTOMySQL', -- Linked server name (it can be anything)
@srvproduct=N'MySQLDatabase', -- Keep as it is
@provider=N'MSDASQL', -- Keep as it is
@datasrc=N'MYSQLODBCConnection' --DSN Name Created in Step 3 (very important)
/* For security reasons the linked server remote logins password is changed with ######## */
EXEC master.dbo.sp_addlinkedsrvlogin
@rmtsrvname=N'LinkedServerTOMySQL',
@useself=N'False',
@locallogin=NULL,
@rmtuser=N'root',
@rmtpassword='change thepasswordhere'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'collation compatible', @optvalue=N'false'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'data access', @optvalue=N'true'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'dist', @optvalue=N'false'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'pub', @optvalue=N'false'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'rpc', @optvalue=N'false'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'rpc out', @optvalue=N'false'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'sub', @optvalue=N'false'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'connect timeout', @optvalue=N'0'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'collation name', @optvalue=null
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'lazy schema validation', @optvalue=N'false'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'query timeout', @optvalue=N'0'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'use remote collation', @optvalue=N'true'
--======================================================================================================
Enable Distributed Queries (OpenQuery) in SQL Instance
By default in SQL Server 2005 Distributed Queries are disabled. You have to enable it using the following script. (Note : In SQL Server 2000 no need to run this script)
Copy this script to a query analyzer and run
EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE
EXEC sys.sp_configure N'Ad Hoc Distributed Queries', N'1'
RECONFIGURE WITH OVERRIDE
Finally, Test the Linked Server and Run a OpenQuer against the LinkedServer Configured
Check the following Screen
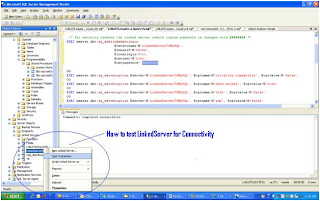
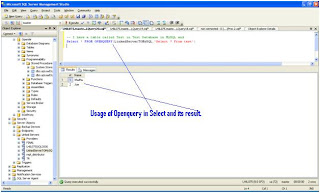
Restart Database Engine and SQL Server Agent
Once you have completed all the steps you may restart the services. I have not tested this whether you need to restart it or not
Summary :
If anyone feels some screen shots are missing please drop a comment.
Tested Environment :
Operating System : Windows XP, Windows 2000, Windows 2003
SQL Server : SQL Server 2005, (Note : I have not tested SQL Server 2000 but I feel it should work)
MySQL : MySQL Server 5.0
MySQL ODBC : ODBC 3.51
High level Steps
• Download and Install ODBC Driver from MYSQL Site
• Create ODBC DSN
• Create Linked Server in SQL Server
• Configure Provider
• Create linked server
• Enable OpenQuery in SQL Server instance
• Create Openquery script
Step 1 : Download MySQL ODBC Connector
Download MySQL Connector/ODBC 3.51 from : http://dev.mysql.com/downloads/connector/odbc/3.51.html
Download the ODBC connector for your Operating System. I have windows xp , so I will download Windows MSI installer (x86)

Step 2 : Install ODBC connector
Double click the downloaded file




At last screen you will get a Finish button and click that. Now You have installed ODBC connector for MySQL.
Step 3 : Create System DSN for MYSql ODBC Driver
Windows Start --- >> Run --- >> odbcad32
Or
Windows Start --- >> Control Panel ->Performance and Maintenance (in XP) --- >> Administrative Tools -> Data Sources (ODBC)









Step 3 : Create Linked Server in SQL Server 2005.
Change the properties of the Provider
Select the properties as shown in the screens



--======================================================================================================
Script to Create Linked Server
It is always better to create linked server using Script than GUI. You have more control and script of course is more readable. I am not giving the screen shot for this steps. Copy paste the script to a query analyzer change DSN Name, Username, Password and run.
--======================================================================================================
/****** Object: LinkedServer [LinkedServerTOMySQL] Script Date: 08/28/2008 11:40:28 ******/
EXEC master.dbo.sp_addlinkedserver
@server = N'LinkedServerTOMySQL',
@srvproduct=N'MySQLDatabase',
@provider=N'MSDASQL',
@datasrc=N'MYSQLODBCConnection'
Parameter Explanation
@server = N'LinkedServerTOMySQL', -- Linked server name (it can be anything)
@srvproduct=N'MySQLDatabase', -- Keep as it is
@provider=N'MSDASQL', -- Keep as it is
@datasrc=N'MYSQLODBCConnection' --DSN Name Created in Step 3 (very important)
/* For security reasons the linked server remote logins password is changed with ######## */
EXEC master.dbo.sp_addlinkedsrvlogin
@rmtsrvname=N'LinkedServerTOMySQL',
@useself=N'False',
@locallogin=NULL,
@rmtuser=N'root',
@rmtpassword='change thepasswordhere'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'collation compatible', @optvalue=N'false'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'data access', @optvalue=N'true'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'dist', @optvalue=N'false'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'pub', @optvalue=N'false'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'rpc', @optvalue=N'false'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'rpc out', @optvalue=N'false'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'sub', @optvalue=N'false'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'connect timeout', @optvalue=N'0'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'collation name', @optvalue=null
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'lazy schema validation', @optvalue=N'false'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'query timeout', @optvalue=N'0'
GO
EXEC master.dbo.sp_serveroption @server=N'LinkedServerTOMySQL', @optname=N'use remote collation', @optvalue=N'true'
--======================================================================================================
Enable Distributed Queries (OpenQuery) in SQL Instance
By default in SQL Server 2005 Distributed Queries are disabled. You have to enable it using the following script. (Note : In SQL Server 2000 no need to run this script)
Copy this script to a query analyzer and run
EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE
EXEC sys.sp_configure N'Ad Hoc Distributed Queries', N'1'
RECONFIGURE WITH OVERRIDE
Finally, Test the Linked Server and Run a OpenQuer against the LinkedServer Configured
Check the following Screen


Restart Database Engine and SQL Server Agent
Once you have completed all the steps you may restart the services. I have not tested this whether you need to restart it or not
Summary :
If anyone feels some screen shots are missing please drop a comment.
Saturday, August 9, 2008
Creating Files from the images stored in Binary format in the database table.
Problem :-
Images are stored in a database table-Varbinary (SQL Server 2005) column. Form the stored images we need to create individual image files.
Solution :
BCP QUERYOUT with little format file tweaking can be a wonderful solution for this. You can include this BCP queryout in a XP_CMDShell dynamic sql from SQL Env and it will provide a simple solution to this complex requirement.
Demo environment details
Database : AdventureWorks
Table : ProductionPhoto
Image Column : LargePhoto
There are 101 rows in this table, each one having a LargePhoto column with some image. We need to create 101 JPG files from this table. Here we go…
Step 1 : Creation of Format File
C:\>bcp AdventureWorks.Production.ProductPhoto format nul -T -n -f c:\PP.fmt

Step 2 : Format file will looks something like this
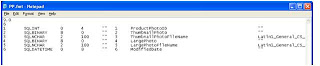
Step 3 : Tweak Format file : We need to get the LargePhoto column binary data.
• Remove all column except LargePhoto
• Change Prefix of LargePhoto column from 8 to 0 (zero)
• Change Number of column from 6 to 1
• Change column sequence from 4 to 1
• After the ncessary modification the format file should look like next sceen

Step 4 : Use BCP QUERYOUT to create Image files
My BCP QUERYOUT query is this
--=====================================================================================
C:\>bcp "SELECT top 1 LargePhoto FROM AdventureWorks.Production.ProductPhoto wh
ere ProductPhotoID=69" queryout c:\ProductPhotoID_69.jpg -T -fC:\PP.fmt
Starting copy...
1 rows copied.
Network packet size (bytes): 4096
Clock Time (ms.) Total : 1 Average : (1000.00 rows per sec.)
C:\>
=====================================================================================
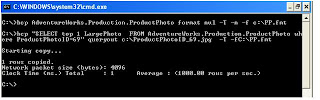
The above BCP Queryout statement is created a file ProductPhotoID_69.jpg . Now let us go and open that form windows
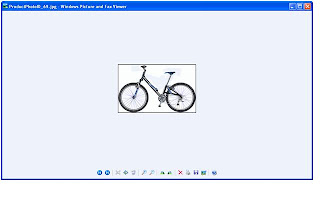
Double click the file and the file opened
Step 5 : Loop through all the records in this table and create respective files of each row in C:\Photo folder
--==============================================================================
SET NOCOUNT ON
DECLARE @ProductPhotoID int, @Sqlstmt varchar(4000),@LargePhotoFileName varchar(200)
DECLARE Cursor_ProductPhoto CURSOR FOR
SELECT ProductPhotoID, LargePhotoFileName
from AdventureWorks.Production.ProductPhoto
ORDER BY ProductPhotoID
OPEN Cursor_ProductPhoto
FETCH NEXT FROM Cursor_ProductPhoto
INTO @ProductPhotoID, @LargePhotoFileName
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT @LargePhotoFileName
-- Framing DynamicSQL for XP_CMDshell
Set @Sqlstmt='bcp "SELECT top 1 LargePhoto FROM AdventureWorks.Production.ProductPhoto where ProductPhotoID='+str(@ProductPhotoID)+'" queryout c:\Photo\'+ltrim(@LargePhotoFileName)+' -T -fC:\PP.fmt'
print @sqlstmt
exec xp_cmdshell @sqlstmt
FETCH NEXT FROM Cursor_ProductPhoto
INTO @ProductPhotoID, @LargePhotoFileName
END
CLOSE Cursor_ProductPhoto
DEALLOCATE Cursor_ProductPhoto
--==============================================================================
Check this Screen. The above script has created individual files in this folder
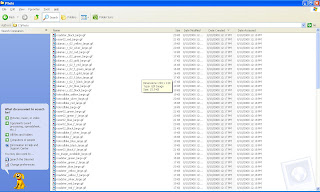
Summary :-
This solution provides very simple method to create files from the binary stored in Database by little tweaking in Format file. If you want to keep a backup of Images in file system format then this method can really help.
Images are stored in a database table-Varbinary (SQL Server 2005) column. Form the stored images we need to create individual image files.
Solution :
BCP QUERYOUT with little format file tweaking can be a wonderful solution for this. You can include this BCP queryout in a XP_CMDShell dynamic sql from SQL Env and it will provide a simple solution to this complex requirement.
Demo environment details
Database : AdventureWorks
Table : ProductionPhoto
Image Column : LargePhoto
There are 101 rows in this table, each one having a LargePhoto column with some image. We need to create 101 JPG files from this table. Here we go…
Step 1 : Creation of Format File
C:\>bcp AdventureWorks.Production.ProductPhoto format nul -T -n -f c:\PP.fmt

Step 2 : Format file will looks something like this

Step 3 : Tweak Format file : We need to get the LargePhoto column binary data.
• Remove all column except LargePhoto
• Change Prefix of LargePhoto column from 8 to 0 (zero)
• Change Number of column from 6 to 1
• Change column sequence from 4 to 1
• After the ncessary modification the format file should look like next sceen

Step 4 : Use BCP QUERYOUT to create Image files
My BCP QUERYOUT query is this
--=====================================================================================
C:\>bcp "SELECT top 1 LargePhoto FROM AdventureWorks.Production.ProductPhoto wh
ere ProductPhotoID=69" queryout c:\ProductPhotoID_69.jpg -T -fC:\PP.fmt
Starting copy...
1 rows copied.
Network packet size (bytes): 4096
Clock Time (ms.) Total : 1 Average : (1000.00 rows per sec.)
C:\>
=====================================================================================

The above BCP Queryout statement is created a file ProductPhotoID_69.jpg . Now let us go and open that form windows

Double click the file and the file opened

Step 5 : Loop through all the records in this table and create respective files of each row in C:\Photo folder
--==============================================================================
SET NOCOUNT ON
DECLARE @ProductPhotoID int, @Sqlstmt varchar(4000),@LargePhotoFileName varchar(200)
DECLARE Cursor_ProductPhoto CURSOR FOR
SELECT ProductPhotoID, LargePhotoFileName
from AdventureWorks.Production.ProductPhoto
ORDER BY ProductPhotoID
OPEN Cursor_ProductPhoto
FETCH NEXT FROM Cursor_ProductPhoto
INTO @ProductPhotoID, @LargePhotoFileName
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT @LargePhotoFileName
-- Framing DynamicSQL for XP_CMDshell
Set @Sqlstmt='bcp "SELECT top 1 LargePhoto FROM AdventureWorks.Production.ProductPhoto where ProductPhotoID='+str(@ProductPhotoID)+'" queryout c:\Photo\'+ltrim(@LargePhotoFileName)+' -T -fC:\PP.fmt'
print @sqlstmt
exec xp_cmdshell @sqlstmt
FETCH NEXT FROM Cursor_ProductPhoto
INTO @ProductPhotoID, @LargePhotoFileName
END
CLOSE Cursor_ProductPhoto
DEALLOCATE Cursor_ProductPhoto
--==============================================================================
Check this Screen. The above script has created individual files in this folder

Summary :-
This solution provides very simple method to create files from the binary stored in Database by little tweaking in Format file. If you want to keep a backup of Images in file system format then this method can really help.
Wednesday, August 6, 2008
Microsoft SQL Server 2008 Released
Finally Microsoft SQL Server 2008 RTM version is released today. It was suppose to release almost one year back but somehow did not. There are seven editions in SQL Server 2008.
In a press release, Microsoft cited several large enterprise customers who are testing SQL Server 2008, including Xerox, Siemens, Clear Channel Communications and Fidelity Investments.
In a press release, Microsoft cited several large enterprise customers who are testing SQL Server 2008, including Xerox, Siemens, Clear Channel Communications and Fidelity Investments.
Thursday, July 24, 2008
Best Practices, Design and Development Guidelines for SQL Server
There are many resources available in the net but here I have a list of Best Practices,Design Guidelines and General Guidelines in Database Development and Designing specifically for SQL Server.
Best Practices
1. Use Stored Procedure: Benefits are as follows :-
(a) Code reusability
(b) Security : You can control permission on sp
(c) Execution plan reusability : Though adhoc query also create and reuse plan, the plan is reused only when the query is textual match and the datatypes are matching with the previous call. Any datatype or you have an extra space in the query then new plan is created
Eg.
-------------------------------------------------------------------------------------
Select Sal from Employee where sal=$10 --Money
--And
Select Sal from Employee where sal=10 -- Int
-------------------------------------------------------------------------------------
Above statements will create different execution plan because the datatype of value is different.
(d) Procedure gives more Readability and Manageability.
2. Use Fully Qualified Name for objects : This is very significant. You must use fully qualified name when you refer any object in SQL Server. Ie. SchemaName.ObjectName. Because, when the execution plan is prepared by the query engine , in the binding process, Query engine has to resolve the Object existence. If you specify the fully qualified name the object resolution become easy for the engine and also it will be more readable.
3. Avoid using Scalar Function in SELECT statement: Recently I faced this issue and I emphasis this point. Never use Scalar function inside a query which returns a large number of rows. Scalar function behave like a cursor when you use Scalar function inside a query which returns large number of rows . Change the scalar function to Inline or Multiline table function or a view.
4. Avoid Mixing-up DML and DDL statement on a temp table inside sp : This is very important. When you Create a temptable (#table) and ALTER the same temptable in the same storedprocedure later, this DDL and DML mix-up causes the stored procedure to get recompiled. So, if a stored procedure is getting recompiled in each call check this point.
5. Select only the required columns: Select only the required column in select statement. Usage of SELECT * can be the cause of NOT using the indexes available on the table . Also if you are selecting more data then you are doing more IO. In short we should limit the IO.
6. Avoid Usage of HINTS : HINTS prevent Query engine automated optimization capability. You may find a hint gives you better performance on a particular scenario. But it may behave differently as the data grows or when scenario changes. Check this KB on HINTS http://msdn.microsoft.com/en-us/library/ms187713.aspx
7. Use Table variable and Temp table as far as possible: You must use Table variable (@TableName) or Temp table (#TableName) for intermediate storage of records in an procedure. Avoid using Table variable for large record set. There are pros and cons between Table variable and Temp table, but in general, if the record set is small you should go for Table variable.
8. Use SET NOCOUNT ON : Basically, you must reduce the data transferred on the network. Database Engine, return the number of rows effected by the statements to the client which is unnecessary and you can avoid that using this statement. It is a must in all Stored procedure.
9. Do not change SET OPTION In connection: Changing SET Option during connection or anywhere else will cause the stored procedure to recompile. Refer this KB for more info http://www.microsoft.com/technet/prodtechnol/sql/2005/recomp.mspx
10. EXISTS vs IN : IN Operator can easily be replaced by EXISTS which is more optimized for correlated queries. But you may find IN better for small tables.
11. Keep the transaction as short as possible: Deadlock is a outcome of ill-formed query. You must keep the transaction as short as possible to avoid dead lock. And also refer the object in the same order inside transaction.
12. Avoid user input inside a transaction: Do not accept a user input inside a transaction.
13. Avoid doing Front-End work in Databases : String processing , Ordering , Conversion etc can easily be done at the client side and you should avoid doing these kind of work in Database. The point here is, you should have a clear segregation of tasks between Data Layer, Data Access Layer (DAL) and Business Layer. For example, you can easily number your rows in client side where as if you do that in Database you have to use a Function or extra join which can be avoided.
14. Avoid Function in select statement: Any functions like CONVERT(),CAST,ISNULL usage in query may ignore the indexes available on the table.
15. Do not use EXEC (‘String’) , use sp_executeSql : As far as possible you try to avoid Dynamic SQL. If there is no other option use sp_ExecuteSQL DO NOT USE EXEC(‘string’). Because EXEC statement is prone to SQL Injection and it is not parametrized query which can re-use execution plan.
16. Use proper size for the input parameter: This is one of the step to avoid SQL Injection and also the reduce the memory usage.
17. Do not keep the name of sp with sp_ prefix: Naming convention is very important. Do not name the storedprocedures with SP_ as prefix (eg sp_ somespname ) because this naming convention is used for system stored procedure in MS SQL Server.
18. USE WHERE Condition as far as possible: Basically, you should limit the rows fetched by the query.
19. Avoid Negative operator : Avoid using <> , NOT IN, NOT EXISTS kind of operator because it causes a table scan. Query engine has to ensure there is not data till the last row is read.
20. Avoid Cursor /loops: In SET Based operation, in general looping can be avoided.
21. Avoid using Like ‘% %’ : If you use % in both side of the searching value, the query will go for table scan which should be avoided. If the application is more text searching kind go for Full Text Index.
22. Do not use WITH Recompile : Usage of WITH Recompile causes the procedure to recompile each time it call. You must avoid this command.
23. JOIN Consideration : When you JOIN two table consider these points
(a) Avoid using negative operator (<> ,NOT IN) in JOIN
(b) Avoid Like operator in Join
Design Guidelines
1. Create Covering indexes: Create covering indexes. Covering index will have all the data required by the query at the leaf level itself. Covering contains all the columns used in SELECT, WHERE, ORDERBY, JOIN etc.
Eg.
Select Col1,Col2 From YourTableName Where Col3=1 Order by Col4.
The coveing index for the above mentioned query will be
Col1+ col2+ col3+ col4. (Note : Most selective column should come first in the index creation statement)
2. Remove Unwanted indexes : In SQL Server 2005 it is very easy to find unused indexes. Too many or too less indexes on a table are equally bad. If you have unwanted/unused indexes on a table Insert/Update statement will have performance hit and also we all know indexes consume space.
3. Create the indexes most selective column as first column in Index : Index creation has to be done after proper analysis. You must create the index with Most Selective column at first and so on.
4. Formatting the stored procedure and queries : You must have a format / template for each object (sp/function/views) and everyone (the dev team) should stick to the format defined. And also the query has to be formatted well so that it is more readable.
5. Use Identity column if the table is INSERT oriented table as Clustered Index to avoid page split : This is a design and data modeling issue. If you have more insert kind of table (some kind of logging table) then you must go for Identity Column (ever increasing) as Clustered Index. This helps to resolve page split. There may be Hotspot issue (all transaction contending for same page of a table), but I have never faced.
6. Use proper fillfactor for Indexes: Very important to avoid Page Split. In general transactional table can be kept at 80-90 fillfactor.
7. Balanced Normalization / De-normalization: You must have a trade off between Normalization and de-normalization. At time De-normalization can give you better performance at the cost of Data redundancy.
8. Primary Key size and Composite primary key : You must limit the size of the PK because, in a relational database, you may be creating foreign key which refers this primary key. If you have multiple Column in PK (composite PK) or big size , you are knowingly or unknowingly increasing the space usage. If the composite PK contains more than 3 columns then you may go for surrogate key like Identity column as PK.
9. Do not alter system Objects: If your application requires some tweaking of system objects then you are in trouble. The structure of system object can be changed by Microsoft in any release or patches. So avoid such modeling.
Guidelines for Datatype Selection
As a Database architect I believe in the significance of proper datatype selection while designing the tables. if you do a proper analysis of the data and then select the datatype, then you can control the row, page, table size and hence increase the overall performance of the database. Following points you may consider when you design a table :-
1. If your database is to support web-based application better to go for UNICODE for the scalability of the application. (Unicode (nchar, nvarchar) takes 2 bytes per char where as ASCII (char,varchar) datatypes takes 1 bytes per char)
2. If your application is multi-lingual go for UNICODE.
3. If you are planning to include CLRDatatype (SQL Server 2005) in the database go for UNICODE Datatypes , because, if CLRDatatype is going to consume the data then it must be in UNICODE.
4. For numeric column, find the range that column is going to have and then choose the datatype. For eg. You have a table called Department and DepartmentID is the Primarykey Column. You know that the maximum rows in this table is 20-30. In such cases it is recommended to choose TinyINT datatype for this column. Generally keeping all numeric columns type of INT without analyzing the range that column going to support is not at all recommended from storage perspective.
5. Description /Comments /Remarks sort of columns may or may not have data for all the rows. So it is better to go for Variable datatypes like Varchar ,Nvarchar.
6. If you know the column is not nullable and it may contain more or less the same size of the data then for sure go for Fixed datatype like CHAR or NCHAR. Having said that it is important to know that, if you select fixed datatypes and if the column is nullable then, if you do not have any data (null) then also the column will consume the space.
7. If the size of the column is less than 20 char , use fixed width datatypes like NCHAR or CHAR.
8. I have seen in many applications use Decimal to store currency kind of data though the application needs the precision which can be supported by money. So, my point here is, use Money datatype if you need only 4 precision.
9. Use UniqueIdentitifier column as PK and ClusteredIndex or so only when it is unavoidable because UniqueIdentitifier takes 16 Bytes of the space.
General Guidelines
1. Write ANSI standard Code : You must write standard code which will scale your application. ie migration to next version will not be an issue. Do not use Deprecated features. For eg. There are DBCC Command to rebuild index but in SQL Server 2005 in order to standardize things, you have ALTER INDEX command which does the same thing.
2. Do not give Error message which expose your architecture to the frontend: I have seen folks giving very detailed error message which tells you “ blah blah table do not have this rows in blah blah database” kind which can be a invitation to the hacker
3. Use proper Isolation level required for the application: This is very significant. Before going for any isolation level, you must know the implication. All application cannot afford READUNCOMMITTED Isolation level since it can cause data inconsistency issues like Dirty Read, Phantom read, Lost Update etc. WITH NOLOCK Hint is nothing but READ UNCOMMITTED isolation level.
4. Keep the Database Object Scripts in Source Control: We all are aware of this point but generally ignore. This is important for fault tolerance and management when multiple developers are working on same project.
Best Practices
1. Use Stored Procedure: Benefits are as follows :-
(a) Code reusability
(b) Security : You can control permission on sp
(c) Execution plan reusability : Though adhoc query also create and reuse plan, the plan is reused only when the query is textual match and the datatypes are matching with the previous call. Any datatype or you have an extra space in the query then new plan is created
Eg.
-------------------------------------------------------------------------------------
Select Sal from Employee where sal=$10 --Money
--And
Select Sal from Employee where sal=10 -- Int
-------------------------------------------------------------------------------------
Above statements will create different execution plan because the datatype of value is different.
(d) Procedure gives more Readability and Manageability.
2. Use Fully Qualified Name for objects : This is very significant. You must use fully qualified name when you refer any object in SQL Server. Ie. SchemaName.ObjectName. Because, when the execution plan is prepared by the query engine , in the binding process, Query engine has to resolve the Object existence. If you specify the fully qualified name the object resolution become easy for the engine and also it will be more readable.
3. Avoid using Scalar Function in SELECT statement: Recently I faced this issue and I emphasis this point. Never use Scalar function inside a query which returns a large number of rows. Scalar function behave like a cursor when you use Scalar function inside a query which returns large number of rows . Change the scalar function to Inline or Multiline table function or a view.
4. Avoid Mixing-up DML and DDL statement on a temp table inside sp : This is very important. When you Create a temptable (#table) and ALTER the same temptable in the same storedprocedure later, this DDL and DML mix-up causes the stored procedure to get recompiled. So, if a stored procedure is getting recompiled in each call check this point.
5. Select only the required columns: Select only the required column in select statement. Usage of SELECT * can be the cause of NOT using the indexes available on the table . Also if you are selecting more data then you are doing more IO. In short we should limit the IO.
6. Avoid Usage of HINTS : HINTS prevent Query engine automated optimization capability. You may find a hint gives you better performance on a particular scenario. But it may behave differently as the data grows or when scenario changes. Check this KB on HINTS http://msdn.microsoft.com/en-us/library/ms187713.aspx
7. Use Table variable and Temp table as far as possible: You must use Table variable (@TableName) or Temp table (#TableName) for intermediate storage of records in an procedure. Avoid using Table variable for large record set. There are pros and cons between Table variable and Temp table, but in general, if the record set is small you should go for Table variable.
8. Use SET NOCOUNT ON : Basically, you must reduce the data transferred on the network. Database Engine, return the number of rows effected by the statements to the client which is unnecessary and you can avoid that using this statement. It is a must in all Stored procedure.
9. Do not change SET OPTION In connection: Changing SET Option during connection or anywhere else will cause the stored procedure to recompile. Refer this KB for more info http://www.microsoft.com/technet/prodtechnol/sql/2005/recomp.mspx
10. EXISTS vs IN : IN Operator can easily be replaced by EXISTS which is more optimized for correlated queries. But you may find IN better for small tables.
11. Keep the transaction as short as possible: Deadlock is a outcome of ill-formed query. You must keep the transaction as short as possible to avoid dead lock. And also refer the object in the same order inside transaction.
12. Avoid user input inside a transaction: Do not accept a user input inside a transaction.
13. Avoid doing Front-End work in Databases : String processing , Ordering , Conversion etc can easily be done at the client side and you should avoid doing these kind of work in Database. The point here is, you should have a clear segregation of tasks between Data Layer, Data Access Layer (DAL) and Business Layer. For example, you can easily number your rows in client side where as if you do that in Database you have to use a Function or extra join which can be avoided.
14. Avoid Function in select statement: Any functions like CONVERT(),CAST,ISNULL usage in query may ignore the indexes available on the table.
15. Do not use EXEC (‘String’) , use sp_executeSql : As far as possible you try to avoid Dynamic SQL. If there is no other option use sp_ExecuteSQL DO NOT USE EXEC(‘string’). Because EXEC statement is prone to SQL Injection and it is not parametrized query which can re-use execution plan.
16. Use proper size for the input parameter: This is one of the step to avoid SQL Injection and also the reduce the memory usage.
17. Do not keep the name of sp with sp_ prefix: Naming convention is very important. Do not name the storedprocedures with SP_ as prefix (eg sp_ somespname ) because this naming convention is used for system stored procedure in MS SQL Server.
18. USE WHERE Condition as far as possible: Basically, you should limit the rows fetched by the query.
19. Avoid Negative operator : Avoid using <> , NOT IN, NOT EXISTS kind of operator because it causes a table scan. Query engine has to ensure there is not data till the last row is read.
20. Avoid Cursor /loops: In SET Based operation, in general looping can be avoided.
21. Avoid using Like ‘% %’ : If you use % in both side of the searching value, the query will go for table scan which should be avoided. If the application is more text searching kind go for Full Text Index.
22. Do not use WITH Recompile : Usage of WITH Recompile causes the procedure to recompile each time it call. You must avoid this command.
23. JOIN Consideration : When you JOIN two table consider these points
(a) Avoid using negative operator (<> ,NOT IN) in JOIN
(b) Avoid Like operator in Join
Design Guidelines
1. Create Covering indexes: Create covering indexes. Covering index will have all the data required by the query at the leaf level itself. Covering contains all the columns used in SELECT, WHERE, ORDERBY, JOIN etc.
Eg.
Select Col1,Col2 From YourTableName Where Col3=1 Order by Col4.
The coveing index for the above mentioned query will be
Col1+ col2+ col3+ col4. (Note : Most selective column should come first in the index creation statement)
2. Remove Unwanted indexes : In SQL Server 2005 it is very easy to find unused indexes. Too many or too less indexes on a table are equally bad. If you have unwanted/unused indexes on a table Insert/Update statement will have performance hit and also we all know indexes consume space.
3. Create the indexes most selective column as first column in Index : Index creation has to be done after proper analysis. You must create the index with Most Selective column at first and so on.
4. Formatting the stored procedure and queries : You must have a format / template for each object (sp/function/views) and everyone (the dev team) should stick to the format defined. And also the query has to be formatted well so that it is more readable.
5. Use Identity column if the table is INSERT oriented table as Clustered Index to avoid page split : This is a design and data modeling issue. If you have more insert kind of table (some kind of logging table) then you must go for Identity Column (ever increasing) as Clustered Index. This helps to resolve page split. There may be Hotspot issue (all transaction contending for same page of a table), but I have never faced.
6. Use proper fillfactor for Indexes: Very important to avoid Page Split. In general transactional table can be kept at 80-90 fillfactor.
7. Balanced Normalization / De-normalization: You must have a trade off between Normalization and de-normalization. At time De-normalization can give you better performance at the cost of Data redundancy.
8. Primary Key size and Composite primary key : You must limit the size of the PK because, in a relational database, you may be creating foreign key which refers this primary key. If you have multiple Column in PK (composite PK) or big size , you are knowingly or unknowingly increasing the space usage. If the composite PK contains more than 3 columns then you may go for surrogate key like Identity column as PK.
9. Do not alter system Objects: If your application requires some tweaking of system objects then you are in trouble. The structure of system object can be changed by Microsoft in any release or patches. So avoid such modeling.
Guidelines for Datatype Selection
As a Database architect I believe in the significance of proper datatype selection while designing the tables. if you do a proper analysis of the data and then select the datatype, then you can control the row, page, table size and hence increase the overall performance of the database. Following points you may consider when you design a table :-
1. If your database is to support web-based application better to go for UNICODE for the scalability of the application. (Unicode (nchar, nvarchar) takes 2 bytes per char where as ASCII (char,varchar) datatypes takes 1 bytes per char)
2. If your application is multi-lingual go for UNICODE.
3. If you are planning to include CLRDatatype (SQL Server 2005) in the database go for UNICODE Datatypes , because, if CLRDatatype is going to consume the data then it must be in UNICODE.
4. For numeric column, find the range that column is going to have and then choose the datatype. For eg. You have a table called Department and DepartmentID is the Primarykey Column. You know that the maximum rows in this table is 20-30. In such cases it is recommended to choose TinyINT datatype for this column. Generally keeping all numeric columns type of INT without analyzing the range that column going to support is not at all recommended from storage perspective.
5. Description /Comments /Remarks sort of columns may or may not have data for all the rows. So it is better to go for Variable datatypes like Varchar ,Nvarchar.
6. If you know the column is not nullable and it may contain more or less the same size of the data then for sure go for Fixed datatype like CHAR or NCHAR. Having said that it is important to know that, if you select fixed datatypes and if the column is nullable then, if you do not have any data (null) then also the column will consume the space.
7. If the size of the column is less than 20 char , use fixed width datatypes like NCHAR or CHAR.
8. I have seen in many applications use Decimal to store currency kind of data though the application needs the precision which can be supported by money. So, my point here is, use Money datatype if you need only 4 precision.
9. Use UniqueIdentitifier column as PK and ClusteredIndex or so only when it is unavoidable because UniqueIdentitifier takes 16 Bytes of the space.
General Guidelines
1. Write ANSI standard Code : You must write standard code which will scale your application. ie migration to next version will not be an issue. Do not use Deprecated features. For eg. There are DBCC Command to rebuild index but in SQL Server 2005 in order to standardize things, you have ALTER INDEX command which does the same thing.
2. Do not give Error message which expose your architecture to the frontend: I have seen folks giving very detailed error message which tells you “ blah blah table do not have this rows in blah blah database” kind which can be a invitation to the hacker
3. Use proper Isolation level required for the application: This is very significant. Before going for any isolation level, you must know the implication. All application cannot afford READUNCOMMITTED Isolation level since it can cause data inconsistency issues like Dirty Read, Phantom read, Lost Update etc. WITH NOLOCK Hint is nothing but READ UNCOMMITTED isolation level.
4. Keep the Database Object Scripts in Source Control: We all are aware of this point but generally ignore. This is important for fault tolerance and management when multiple developers are working on same project.
Monday, July 21, 2008
Visio - ERROR – Failed to Initialize the Modeling Engine.
Recently I reinstalled Visio 2003 Enterprise Architecture edition and it started popping up the above mentioned error. I was not able to do any Database modeling kind of tasks since the options were not available. I goggled as usual and I found the same issue is being reported by many. The solution for this issue is uninstalling Visio Update patch KB947650. I did the same and it fixed my error
follow these steps :-
Control Panel –
Add or Remove Programs
Check “ Show Updates” check box in Add or Remove programs window
– MS Visio Enterprise Architect
Select KB947650 update and remove it.
follow these steps :-
Control Panel –
Add or Remove Programs
Check “ Show Updates” check box in Add or Remove programs window
– MS Visio Enterprise Architect
Select KB947650 update and remove it.
Tuesday, July 15, 2008
Scalar Function and Performance Issue
Performance tuning is one of the main tasks I do and there is always scope to learn new things in this area. Recently, I got a query which was using a Scalar function takes almost 4 min. When the scalar function is removed it came within one sec. I know scalar function inside a query is not optimized and may be because of that I very rarely use scalar function. But in this particular project, scalar function is very common and tuning query with scalar function is little tricky. Following are the suggestions I got from my MVP friends :-
(a) If possible create a view and join with the view: This was not possible for me since I had to pass the parameter.
(b) You may also create a Inline or multiline table function: I went with this route. I created a multiline function and I tell you the performance was improved manifold.
Sample code
The scalar function was something like returning appointments concatenated string for a given EmployeeID
Same logic in Multiline function which uses FOR XML PATH query
Create function fnConcatMultipleRowValuesToColumn ()
Returns @tab Table (EmpID int,con varchar(200))
As
Begin
DECLARE @Designation TABLE (EmpID INT, Code VARCHAR(50))
INSERT @Designation
SELECT 100, 'SR. Engr.' UNION ALL
SELECT 100, 'TL' UNION ALL
SELECT 100, 'PM' UNION ALL
SELECT 200, 'QA' UNION ALL
SELECT 200, 'SR QA' UNION ALL
SELECT 200, 'TL QA'UNION ALL
SELECT 300, 'DBA'UNION ALL
SELECT 300, 'SR. DBA'UNION ALL
SELECT 300, 'TL DBA'
-- Show the expected output
Insert @tab
SELECT DISTINCT s1.EmpID,
STUFF((SELECT DISTINCT TOP 100 PERCENT ',' + s2.CODE FROM @Designation AS s2
WHERE s2.EmpID = s1.EmpID ORDER BY ',' + s2.CODE FOR XML PATH('')), 1, 1, '') AS CODES
FROM @Designation AS s1
ORDER BY s1.EmpID
Return
End
Function Call
Select *From fnConcatMultipleRowValuesToColumn ()
Summary :
Avoid Scalar functions as far as possible. This was introduced in SQL Server 2000 and there may be certain scenario where it may be useful like encapsulation. But when you use scalar function within a select statement which returns many rows may trouble you.
Few good resources to refer
http://sqlblog.com/blogs/adam_machanic/archive/2006/08/04/scalar-functions-inlining-and-performance-an-entertaining-title-for-a-boring-post.aspx
http://www.sqlservercentral.com/Forums/Topic446308-360-1.aspx
(a) If possible create a view and join with the view: This was not possible for me since I had to pass the parameter.
(b) You may also create a Inline or multiline table function: I went with this route. I created a multiline function and I tell you the performance was improved manifold.
Sample code
The scalar function was something like returning appointments concatenated string for a given EmployeeID
Same logic in Multiline function which uses FOR XML PATH query
Create function fnConcatMultipleRowValuesToColumn ()
Returns @tab Table (EmpID int,con varchar(200))
As
Begin
DECLARE @Designation TABLE (EmpID INT, Code VARCHAR(50))
INSERT @Designation
SELECT 100, 'SR. Engr.' UNION ALL
SELECT 100, 'TL' UNION ALL
SELECT 100, 'PM' UNION ALL
SELECT 200, 'QA' UNION ALL
SELECT 200, 'SR QA' UNION ALL
SELECT 200, 'TL QA'UNION ALL
SELECT 300, 'DBA'UNION ALL
SELECT 300, 'SR. DBA'UNION ALL
SELECT 300, 'TL DBA'
-- Show the expected output
Insert @tab
SELECT DISTINCT s1.EmpID,
STUFF((SELECT DISTINCT TOP 100 PERCENT ',' + s2.CODE FROM @Designation AS s2
WHERE s2.EmpID = s1.EmpID ORDER BY ',' + s2.CODE FOR XML PATH('')), 1, 1, '') AS CODES
FROM @Designation AS s1
ORDER BY s1.EmpID
Return
End
Function Call
Select *From fnConcatMultipleRowValuesToColumn ()
Summary :
Avoid Scalar functions as far as possible. This was introduced in SQL Server 2000 and there may be certain scenario where it may be useful like encapsulation. But when you use scalar function within a select statement which returns many rows may trouble you.
Few good resources to refer
http://sqlblog.com/blogs/adam_machanic/archive/2006/08/04/scalar-functions-inlining-and-performance-an-entertaining-title-for-a-boring-post.aspx
http://www.sqlservercentral.com/Forums/Topic446308-360-1.aspx
Sunday, July 13, 2008
Challenges of being a Database Architect
I have been working as a database architect for quite sometimes. Working as a database architect in small organization (for that matter any organization) is very challenging because at times you may be find yourself into the projects which do not have any SLA (Service Level Agreement) or even SRS (Software Requirement Specification). There are many Non-Functional Requirement (NFR), you need to be concerned while conceiving the architecture. If you ignore those, then you are in trouble sooner than later. If you have not judged NFR which is not mentioned anywhere in any documents then it will certainly backfire when you implement the project. I have seen in many projects requires last minutes architectural patch-up because of ignorance or slackness in the Database Architecture’s side. To be in safer side, though there is no SRS or SLA, you should have a list of assumptions in which, whatever concerns you have are mentioned and the assumptions are either agreed or disagreed by the client. If disagree, then client has to mention what are they looking for. By doing this what you achieve is, you are preparing a SRS and SLA by yourself and client is aware of it and approved it knowingly or unknowingly. No need to say, everything has to be properly documented and tracked through mails. In general, following are few NFRs we as a database architect should be aware of :-
(a) Performance is of course the main issue in any project: - Generally, when you conceive the data architecture you should be well aware of the current application(s) performance and its issues. Of course the client must be expecting performance than the existing application (if any) since he/she is spending lot of money on the new one. So when you design the model you should be well aware till what level you must normalize and where you want to de-normalize the data to increase the performance.
(b) Maintainability &supportability: This point is very important. The client should be able to maintain the application and the database without any unreasonable increase in cost . For eg. If you are designing architecture where there is a need of proper fulltime DBA and the client is not aware of it or not ready for it.
(c) Data migration and synchronization issues: - I have seen in many application the client is not aware of the data migration issues and the requirement. The new data model of course has to different from the existing one . If the data structure is changed then the data has to be migrated with lot of transformations. So you as a database architect you should be aware of this task and the risk involved in it.
(d) Authentication method : - A database architect should be well aware of the authentication method you are going to use and the formalities involved in the process .
(e) Security :- This is another important point which may cause major change if you have not analyzed it properly. You should be well aware of the encryption method if the application demands. Also Database architect should be aware of what access method you want to use or whether you are want firewall exception kind.
(f) SQL Injection : Any application which developed on these days should be SQL Injection proof. As a database architect you should not wait for any SRS or SLA for these kind of standard.
(g) Isolation level the application demands: - Very important from the performance point of view. If you are aware of the isolation level requirement for the application, then you can use decide the isolation level accordingly.
(h) Disaster recovery or Fault tolerance required :- This may not be mentioned in any SLA or SRS. But it is understood (or client may think so) that any application should address these requirement by default.
(i) Capacity Planning :- You should be well aware of approximate size of your database. If you are committed to store the images in database for some reasons like security and management, you should do capacity plan accordingly.
(j) Excessive Usage of features: - I want to emphasis this point. If a product offers few advanced features, it does not mean that you must use that in your architecture for the sake of updated technology. You must be aware of the feature inside out and you should use only if it suits you. I have faced such excessive usage of features in couple of projects.
Summary :-
My list may not be the comprehensive one and please feel free to correct my list. My point here is, Database Architect or Architecture is crucial to any project. Basically, if you see, 95% of the applications in this world will be dealing with data in some way or other. So any erroneous decision in database architecture will kill the whole application. To become a successful database architect in you should be aware of the risk involved in this job.
(a) Performance is of course the main issue in any project: - Generally, when you conceive the data architecture you should be well aware of the current application(s) performance and its issues. Of course the client must be expecting performance than the existing application (if any) since he/she is spending lot of money on the new one. So when you design the model you should be well aware till what level you must normalize and where you want to de-normalize the data to increase the performance.
(b) Maintainability &supportability: This point is very important. The client should be able to maintain the application and the database without any unreasonable increase in cost . For eg. If you are designing architecture where there is a need of proper fulltime DBA and the client is not aware of it or not ready for it.
(c) Data migration and synchronization issues: - I have seen in many application the client is not aware of the data migration issues and the requirement. The new data model of course has to different from the existing one . If the data structure is changed then the data has to be migrated with lot of transformations. So you as a database architect you should be aware of this task and the risk involved in it.
(d) Authentication method : - A database architect should be well aware of the authentication method you are going to use and the formalities involved in the process .
(e) Security :- This is another important point which may cause major change if you have not analyzed it properly. You should be well aware of the encryption method if the application demands. Also Database architect should be aware of what access method you want to use or whether you are want firewall exception kind.
(f) SQL Injection : Any application which developed on these days should be SQL Injection proof. As a database architect you should not wait for any SRS or SLA for these kind of standard.
(g) Isolation level the application demands: - Very important from the performance point of view. If you are aware of the isolation level requirement for the application, then you can use decide the isolation level accordingly.
(h) Disaster recovery or Fault tolerance required :- This may not be mentioned in any SLA or SRS. But it is understood (or client may think so) that any application should address these requirement by default.
(i) Capacity Planning :- You should be well aware of approximate size of your database. If you are committed to store the images in database for some reasons like security and management, you should do capacity plan accordingly.
(j) Excessive Usage of features: - I want to emphasis this point. If a product offers few advanced features, it does not mean that you must use that in your architecture for the sake of updated technology. You must be aware of the feature inside out and you should use only if it suits you. I have faced such excessive usage of features in couple of projects.
Summary :-
My list may not be the comprehensive one and please feel free to correct my list. My point here is, Database Architect or Architecture is crucial to any project. Basically, if you see, 95% of the applications in this world will be dealing with data in some way or other. So any erroneous decision in database architecture will kill the whole application. To become a successful database architect in you should be aware of the risk involved in this job.
Wednesday, July 9, 2008
DDL Trigger to prevent creation of SQL Login with Blank Password
There was a query in MSDN forum regarding preventing creation of login with Blank password using T-SQL script. I was clueless about this. Then Rich was referred to Laurentiu Cristofor's blog. There was no direct answer but it give me a wonderful solution which I was not aware. I would like to thank both of them here. Please check the blog entry Here
So I thought to tweak pwdcompare() function and make a DDL Trigger. Here we go…
Create TRIGGER Svr_DDLtrg_Audit_BLANK_PASSWORD
ON All Server
FOR
Create_Login,Alter_Login
AS
SET NOCOUNT ON
BEGIN
DECLARE @Eventdata XML
SET @Eventdata = EVENTDATA()
declare @loginname varchar(100)
select @loginname=@Eventdata.value('(/EVENT_INSTANCE/ObjectName)[1]', 'nvarchar(2000)')
print @loginname
if exists (select 1 from sys.sql_logins where pwdcompare('', password_hash) = 1 and name=@loginname)
begin
Rollback
end
else Print 'good password'
End
Note : I rollback the statement if the password is blank. IF you want to audit or log then you may modify the script accordingly
So I thought to tweak pwdcompare() function and make a DDL Trigger. Here we go…
Create TRIGGER Svr_DDLtrg_Audit_BLANK_PASSWORD
ON All Server
FOR
Create_Login,Alter_Login
AS
SET NOCOUNT ON
BEGIN
DECLARE @Eventdata XML
SET @Eventdata = EVENTDATA()
declare @loginname varchar(100)
select @loginname=@Eventdata.value('(/EVENT_INSTANCE/ObjectName)[1]', 'nvarchar(2000)')
print @loginname
if exists (select 1 from sys.sql_logins where pwdcompare('', password_hash) = 1 and name=@loginname)
begin
Rollback
end
else Print 'good password'
End
Note : I rollback the statement if the password is blank. IF you want to audit or log then you may modify the script accordingly
Tuesday, July 1, 2008
Best Practices - Datatype Selection while designing tables
• If your database is to support web-based application better to go for UNICODE (Unicode like nchar, nvarchar 2 bytes per char where as ASCII datatypes takes 1 bytes per char) datatypes because you may be going to support different types of clients.
• If your application is multi-lingual go for UNICODE.
• If you are planning to include CLRDatatype (SQL Server 2005) in the database go for UNICODE Datatypes instead of ASCII Datatypes, because, if CLRDatatype is going to consume the data then it must be in UNICODE.
• For numeric column, find the range that column is going to have and then choose the datatype. For eg. If you are sure that the column cannot have more than 255 like DepartmentID in a small organization may not go probably beyond 10 or 20. In such cases it is recommended to choose TinyINT datatype. Generally keeping all integer columns type INT without analyzing the range that going to support is not at all recommended from storage perspective.
• Description /Comments /Remarks sort of columns may or may not have data for all the rows. So it is better to go for Variable datatypes like Varchar ,Nvarchar.
• If you know the column is not nullable and it may contain more or less the same size of the data then for sure go for Fixed datatype like CHAR or NCHAR. Having said that it is important to know that, if you select fixed datatypes and if the column is nullable then if you donot have any data (null) then also the column will consume the space.
• If the size of the column is less than 10 char , use fixed width datatypes like NCHAR or CHAR.
• I have seen in many applications use Decimal to store currency kind of data though the application need less precision which can be supported by money. So, my point is, use Money datatype if you need only 4 precision.
• Use UniqueIdentitifier column as PK and CI or so only when it is unavoidable because UniqueIdentitifier takes 16 Bytes of the space.
Note : The point I want to make here is, if you do a proper analysis of the data and then select the datatype then you can control the row, page, table size and hence increase the performance.
• If your application is multi-lingual go for UNICODE.
• If you are planning to include CLRDatatype (SQL Server 2005) in the database go for UNICODE Datatypes instead of ASCII Datatypes, because, if CLRDatatype is going to consume the data then it must be in UNICODE.
• For numeric column, find the range that column is going to have and then choose the datatype. For eg. If you are sure that the column cannot have more than 255 like DepartmentID in a small organization may not go probably beyond 10 or 20. In such cases it is recommended to choose TinyINT datatype. Generally keeping all integer columns type INT without analyzing the range that going to support is not at all recommended from storage perspective.
• Description /Comments /Remarks sort of columns may or may not have data for all the rows. So it is better to go for Variable datatypes like Varchar ,Nvarchar.
• If you know the column is not nullable and it may contain more or less the same size of the data then for sure go for Fixed datatype like CHAR or NCHAR. Having said that it is important to know that, if you select fixed datatypes and if the column is nullable then if you donot have any data (null) then also the column will consume the space.
• If the size of the column is less than 10 char , use fixed width datatypes like NCHAR or CHAR.
• I have seen in many applications use Decimal to store currency kind of data though the application need less precision which can be supported by money. So, my point is, use Money datatype if you need only 4 precision.
• Use UniqueIdentitifier column as PK and CI or so only when it is unavoidable because UniqueIdentitifier takes 16 Bytes of the space.
Note : The point I want to make here is, if you do a proper analysis of the data and then select the datatype then you can control the row, page, table size and hence increase the performance.
Monday, June 30, 2008
FAQ : Explain a scenario which supports vertical partitioning of a table in SQL Server.
The scenario may be different according to the SQL Server Version you have (SQL 7.0, SQL 2000, SQL 2005). I will be covering SQL Server 2000 and 2005
SQL Server 2000.
In SQL Server (in 2000 and 2005) the IN_ROW_DATA or the row size of a table can have only max 8060 bytes. If you have a table which contains 4 columns of varchar (3000) then though you can create the table but if the data being inserted is more than 8060 bytes then the insert will fail. So what we generally do is, we vertically partition the table to two or more table as per the requirement and keep ONE to ONE relation between all the tables. So this is a valid reason to partition your table vertically. When you do vertical partitioning, try to keep most commonly used small size column in single table.
SQL Server 2005
In SQL Server 2005, the above mentioned problem of SQL Server 2000 is not there because of the storage architecture change called ROW_OVERFLOW_DATA. Ie. In SQL Server 2005 you can have a row which exceed 8060 bytes provided the columns are variable types(Varchar,nvarchar). What Database engine internally does is, it keep all the variable datatypes (varchar, nvarchar )columns data in ROW_OVERFLOW_DATA page. Precisely, the Row size limitation is only applicable to fixed size columns like CHAR, NCHAR. So SQL Server 2000 scenario of partitioning table because of the row size exceeds 8060 bytes is not valid in SQL Server 2005.
But there is a valid reason to do vertical partition of the table in SQL Server 2005. If you are using ONLINE INDEX feature of SQL Server 2005 then you cannot use LOB data as a part of index at the leaf level. And you want to use the LOB column in Index because of the performance benefit it provides. In that case best method is to partition the table vertically in such a way that, keep the small ,mostly used columns in single table (like product detailed description may not be asked frequently by the user) and the columns those are referred in less frequency in another table. Since you do not have LOB data in the table you can use ONLINE INDEX feature in the table.
SQL Server 2000.
In SQL Server (in 2000 and 2005) the IN_ROW_DATA or the row size of a table can have only max 8060 bytes. If you have a table which contains 4 columns of varchar (3000) then though you can create the table but if the data being inserted is more than 8060 bytes then the insert will fail. So what we generally do is, we vertically partition the table to two or more table as per the requirement and keep ONE to ONE relation between all the tables. So this is a valid reason to partition your table vertically. When you do vertical partitioning, try to keep most commonly used small size column in single table.
SQL Server 2005
In SQL Server 2005, the above mentioned problem of SQL Server 2000 is not there because of the storage architecture change called ROW_OVERFLOW_DATA. Ie. In SQL Server 2005 you can have a row which exceed 8060 bytes provided the columns are variable types(Varchar,nvarchar). What Database engine internally does is, it keep all the variable datatypes (varchar, nvarchar )columns data in ROW_OVERFLOW_DATA page. Precisely, the Row size limitation is only applicable to fixed size columns like CHAR, NCHAR. So SQL Server 2000 scenario of partitioning table because of the row size exceeds 8060 bytes is not valid in SQL Server 2005.
But there is a valid reason to do vertical partition of the table in SQL Server 2005. If you are using ONLINE INDEX feature of SQL Server 2005 then you cannot use LOB data as a part of index at the leaf level. And you want to use the LOB column in Index because of the performance benefit it provides. In that case best method is to partition the table vertically in such a way that, keep the small ,mostly used columns in single table (like product detailed description may not be asked frequently by the user) and the columns those are referred in less frequency in another table. Since you do not have LOB data in the table you can use ONLINE INDEX feature in the table.
Thursday, June 19, 2008
FAQ: How to find the authentication mode of a SQL Server Instance ?
Using System Stored procedure xp_loginconfig
xp_loginconfig system strored procedure will give you the authentication information in SQL Server. You can call the sp without parameter to get detailed information or with “Loging Mode” parameter to get only the Authentication mode.
EG.
EXEC xp_loginconfig 'login mode'
Result
Name Config_Value
login mode Mixed
Read Registry to get the authentication Information.
Another method would be reading Registry. Authentication information can be read from the following registry entry.
HKEY_LOCAL_MACHINE\Software\Microsoft\Microsoft SQL Server\MSSQL.##\MSSQLServer\LoginMode
Note : Change ## the number according to your environment.
Eg.
EXECUTE MASTER..XP_REGREAD
'HKEY_LOCAL_MACHINE', 'SOFTWARE\MICROSOFT\MICROSOFT SQL SERVER\MSSQL.4\MSSQLSERVER',
'LOGINMODE'
Result
Value Data
LoginMode 1
xp_loginconfig system strored procedure will give you the authentication information in SQL Server. You can call the sp without parameter to get detailed information or with “Loging Mode” parameter to get only the Authentication mode.
EG.
EXEC xp_loginconfig 'login mode'
Result
Name Config_Value
login mode Mixed
Read Registry to get the authentication Information.
Another method would be reading Registry. Authentication information can be read from the following registry entry.
HKEY_LOCAL_MACHINE\Software\Microsoft\Microsoft SQL Server\MSSQL.##\MSSQLServer\LoginMode
Note : Change ## the number according to your environment.
Eg.
EXECUTE MASTER..XP_REGREAD
'HKEY_LOCAL_MACHINE', 'SOFTWARE\MICROSOFT\MICROSOFT SQL SERVER\MSSQL.4\MSSQLSERVER',
'LOGINMODE'
Result
Value Data
LoginMode 1
Wednesday, June 18, 2008
FAQ : How to find the Index Creation /Rebuild Date in SQL Server
AFAIK, there is no system object gives you the information of Index creation Date in SQL Server. If the Clustered index is on PK then the creation date can get from sysobjects or sys.objects. But that is not the case always.
This query which uses STATS_DATE() function to get the STATISTICS updated date. This will not give you accurate result if you are updating STATISTICS explicitly. The logic behind the query is, if you rebuild indexes the STATISTICS are also being updated at the same time. So if you are not explicitly updating STATISTICS using UPDATE STATISTICS tableName command , then this query will give you the correct information
--In SQL Server 2000
Select Name as IndexName,
STATS_DATE ( id , indid ) as IndexCreatedDate
From sysindexes where id=object_id('HumanResources.Employee')
-- In SQL Server 2005
Select Name as IndexName,
STATS_DATE ( object_id , index_id ) as IndexCreatedDate
From sys.indexes where object_id=object_id('HumanResources.Employee')
This query which uses STATS_DATE() function to get the STATISTICS updated date. This will not give you accurate result if you are updating STATISTICS explicitly. The logic behind the query is, if you rebuild indexes the STATISTICS are also being updated at the same time. So if you are not explicitly updating STATISTICS using UPDATE STATISTICS tableName command , then this query will give you the correct information
--In SQL Server 2000
Select Name as IndexName,
STATS_DATE ( id , indid ) as IndexCreatedDate
From sysindexes where id=object_id('HumanResources.Employee')
-- In SQL Server 2005
Select Name as IndexName,
STATS_DATE ( object_id , index_id ) as IndexCreatedDate
From sys.indexes where object_id=object_id('HumanResources.Employee')
Sunday, June 1, 2008
Cumulative update package 7 for SQL Server 2005 Service Pack 2
Check out Cumulative update package 7 for SQL Server 2005 Service Pack 2 here
http://support.microsoft.com/kb/949095/en-us.
Check the bug fix list and if your application need that bug fix then only apply cummulative hotfix in Production env.
http://support.microsoft.com/kb/949095/en-us.
Check the bug fix list and if your application need that bug fix then only apply cummulative hotfix in Production env.
How to assign XML output of select * FROM Yourtable FOR XML AUTO query to a variable
declare @DataXML xml
set @DataXML =(SELECT * FROM YourTable FOR XML AUTO, ELEMENTS)
select @DataXML
set @DataXML =(SELECT * FROM YourTable FOR XML AUTO, ELEMENTS)
select @DataXML
FAQ : What is the difference between Lazywriter and Checkpoint in SQL Server
Lazywriter
The lazywriter thread sleeps for a specific interval of time. When it is restarted, it examines the size of the free buffer list. If the free buffer list is below a certain point, dependent on the size of the cache, the lazywriter thread scans the buffer cache to reclaim unused pages. It then writes dirty pages that have a reference count of 0. On the Windows 2000, Windows Server 2003, and Windows XP operating systems, most of the work populating the free buffer list and writing dirty pages is performed by the individual threads. The lazywriter thread typically has little to do.
Checkpoint
The checkpoint process also scans the buffer cache periodically and writes any dirty data pages to disk. The difference is that the checkpoint process does not put the buffer page back on the free list. The purpose of the checkpoint process is to minimize the number of dirty pages in memory to reduce the length of a recovery if the server fails. Its purpose is not to populate the free buffer list. Checkpoints typically find few dirty pages to write to disk, because most dirty pages are written to disk by the worker threads or the lazywriter thread in the period between two checkpoints
Refer
http://msdn.microsoft.com/en-us/library/aa175260(SQL.80).aspx
BOL
ms-help://MS.SQLCC.v9/MS.SQLSVR.v9.en/udb9/html/4b0f27cd-f2ac-4761-8135-adc584bd8200.htm
The lazywriter thread sleeps for a specific interval of time. When it is restarted, it examines the size of the free buffer list. If the free buffer list is below a certain point, dependent on the size of the cache, the lazywriter thread scans the buffer cache to reclaim unused pages. It then writes dirty pages that have a reference count of 0. On the Windows 2000, Windows Server 2003, and Windows XP operating systems, most of the work populating the free buffer list and writing dirty pages is performed by the individual threads. The lazywriter thread typically has little to do.
Checkpoint
The checkpoint process also scans the buffer cache periodically and writes any dirty data pages to disk. The difference is that the checkpoint process does not put the buffer page back on the free list. The purpose of the checkpoint process is to minimize the number of dirty pages in memory to reduce the length of a recovery if the server fails. Its purpose is not to populate the free buffer list. Checkpoints typically find few dirty pages to write to disk, because most dirty pages are written to disk by the worker threads or the lazywriter thread in the period between two checkpoints
Refer
http://msdn.microsoft.com/en-us/library/aa175260(SQL.80).aspx
BOL
ms-help://MS.SQLCC.v9/MS.SQLSVR.v9.en/udb9/html/4b0f27cd-f2ac-4761-8135-adc584bd8200.htm
FAQ: How to see what is inside hidden SQL Server 2005 Resource Database (mssqlsystemresource) ?
We all know the master database in SQL Server 2000 was split into two databases in SQL Server 2005. One kept as Master only and the other database is Resource database which is hidden. You can’t see that in Management studio or in any tool. You can see the physical files in Data ( default )folder. The idea behind this separation of objects is to allow very fast and safe upgrades.
If you want to see what is inside this database follow these steps
(a) Stop SQL Server
(b) Copy /paste mssqlsystemresource mdf and ldf files to a new location
(c) Create a new database by Attaching the files from the new location
Now you have the hidden database right in front….
If you want to see what is inside this database follow these steps
(a) Stop SQL Server
(b) Copy /paste mssqlsystemresource mdf and ldf files to a new location
(c) Create a new database by Attaching the files from the new location
Now you have the hidden database right in front….
Upgrading SQL Server from lower version to higher version
Upgrade methodology
(a) First step, before going for any up gradation, you should take full backup of the existing databases including system databases. If anything goes wrong you should have a full backup to fall upon
(b) Run Upgrade advisor : You must run this tool before going for up-gradation. This tool will analyze the existing database in lower version and suggest the potential problems , which may be because of the feature is removed or deprecated in the newer version. Once the upgrade advisor projected any critical problem , you may address the problem before going for up-gradation.
(c) Once you found that there is no major issues reported by Upgrade Advisor, you can plan your up-gradation. You must document each and every step you follow. Also ensure that you have a rollback plan incase anything goes wrong. You must have a proper testing script as well.
(d) You have two choices in upgrade.
In Place upgrade : When you upgrade an earlier SQL Server release in-place through the install upgrade process, all existing application connections remain the same because the server and server instance do not change. This approach requires a more thorough fallback plan and testing. By performing an in-place upgrade, logins and users remain in-sync, database connections remain the same for applications, and SQL Agent jobs and other functionality is concurrently upgraded during the installation. Note that several features, such as log shipping, replication, and cluster environments, have special upgrade considerations.
Side By Side : This method is more or less manual process hence you have full control over the process. You can test the upgrade (migration) process by running parallel system , test it and once proven bring it online. But the disadvantage here is, you have to have additional resource (Hardware/licenses ) . Side by side will be always better since you have the existing instance intact. But at time it may not be feasible because of hardware constraint or Instance Name (like the application demands Default Instance. I would say this method is more clean and controllable.
(e) Once you have upgraded test the system with the application with full load before going online.
Migrating Database in Side by Side Upgrade.
(a) If you have chosen side by side method, after installation of new version of sql server you must migrate the user database from older version sql server instance. There are three options available here.
(a) Backup /Restore : Best and easy method. Benefit is source database can still be online , no downtime
(b) Detach / Attach : You have down time at the source but easy method.
(c) Copy Database Wizard : This tool internally does detach/attach only.
Migration of SQL Logins
This is one of the major disadvantage of Side by Side up-gradation. You must transfer the SQL Logins explicitly. You must transfer the login with the password. Microsoft has provided the script for that. How to Transfer SQL Logins
Migration of SQL Scheduled Jobs
Simple , just need to create the script from source and run that script in target server.
Migration of SSIS Packages
You can use save as option of SSIS package . You can open the package and save the package as file system and then migrate.
(a) First step, before going for any up gradation, you should take full backup of the existing databases including system databases. If anything goes wrong you should have a full backup to fall upon
(b) Run Upgrade advisor : You must run this tool before going for up-gradation. This tool will analyze the existing database in lower version and suggest the potential problems , which may be because of the feature is removed or deprecated in the newer version. Once the upgrade advisor projected any critical problem , you may address the problem before going for up-gradation.
(c) Once you found that there is no major issues reported by Upgrade Advisor, you can plan your up-gradation. You must document each and every step you follow. Also ensure that you have a rollback plan incase anything goes wrong. You must have a proper testing script as well.
(d) You have two choices in upgrade.
In Place upgrade : When you upgrade an earlier SQL Server release in-place through the install upgrade process, all existing application connections remain the same because the server and server instance do not change. This approach requires a more thorough fallback plan and testing. By performing an in-place upgrade, logins and users remain in-sync, database connections remain the same for applications, and SQL Agent jobs and other functionality is concurrently upgraded during the installation. Note that several features, such as log shipping, replication, and cluster environments, have special upgrade considerations.
Side By Side : This method is more or less manual process hence you have full control over the process. You can test the upgrade (migration) process by running parallel system , test it and once proven bring it online. But the disadvantage here is, you have to have additional resource (Hardware/licenses ) . Side by side will be always better since you have the existing instance intact. But at time it may not be feasible because of hardware constraint or Instance Name (like the application demands Default Instance. I would say this method is more clean and controllable.
(e) Once you have upgraded test the system with the application with full load before going online.
Migrating Database in Side by Side Upgrade.
(a) If you have chosen side by side method, after installation of new version of sql server you must migrate the user database from older version sql server instance. There are three options available here.
(a) Backup /Restore : Best and easy method. Benefit is source database can still be online , no downtime
(b) Detach / Attach : You have down time at the source but easy method.
(c) Copy Database Wizard : This tool internally does detach/attach only.
Migration of SQL Logins
This is one of the major disadvantage of Side by Side up-gradation. You must transfer the SQL Logins explicitly. You must transfer the login with the password. Microsoft has provided the script for that. How to Transfer SQL Logins
Migration of SQL Scheduled Jobs
Simple , just need to create the script from source and run that script in target server.
Migration of SSIS Packages
You can use save as option of SSIS package . You can open the package and save the package as file system and then migrate.
Wednesday, May 28, 2008
FAQ : What all are the recommended events for DTA / ITW workload
If you have provided same workload without different events and columns DTA may give you different report. For eg. if you have not included Duration column, DTA will tune the workload in the order they appear in the workload. IF the workload contains duration column , DTA will tune the events in the descending order of the Duration. So to get better result from DTA included recommended events and columns.
Events Recommended
RPC:Completed
RPC:Starting
SP:StmtCompleted
SP:StmtStarting
SQL:BatchCompleted
SQL:BatchStarting
SQL:StmtCompleted
SQL:StmtStarting
Events Recommended
RPC:Completed
RPC:Starting
SP:StmtCompleted
SP:StmtStarting
SQL:BatchCompleted
SQL:BatchStarting
SQL:StmtCompleted
SQL:StmtStarting
Tuesday, May 27, 2008
FAQ : How to search for an object in all the databases
SQL Server 2005
CREATE TABLE #TEMP (TABLENAME SYSNAME, OBJECTNAME SYSNAME,TYPE CHAR(10))
INSERT INTO #TEMP
EXEC SP_MSFOREACHDB "SELECT '?' DATABASENAME, NAME,TYPE FROM ?.SYS.ALL_OBJECTS WHERE NAME='YourSearchingObjectName'"
SELECT * FROM #TEMP
DROP TABLE #TEMP
SQL Server 2000
CREATE TABLE #TEMP (TABLENAME SYSNAME, OBJECTNAME SYSNAME,TYPE CHAR(10))
INSERT INTO #TEMP
EXEC SP_MSFOREACHDB "SELECT '?' DATABASENAME, NAME,XTYPE FROM ?..SYSOBJECTS WHERE NAME='YourSearchingObjectName'"
SELECT * FROM #TEMP
DROP TABLE #TEMP
Note : Replace "YourSearchingObjectName" with the object name which you are searching in the select query
CREATE TABLE #TEMP (TABLENAME SYSNAME, OBJECTNAME SYSNAME,TYPE CHAR(10))
INSERT INTO #TEMP
EXEC SP_MSFOREACHDB "SELECT '?' DATABASENAME, NAME,TYPE FROM ?.SYS.ALL_OBJECTS WHERE NAME='YourSearchingObjectName'"
SELECT * FROM #TEMP
DROP TABLE #TEMP
SQL Server 2000
CREATE TABLE #TEMP (TABLENAME SYSNAME, OBJECTNAME SYSNAME,TYPE CHAR(10))
INSERT INTO #TEMP
EXEC SP_MSFOREACHDB "SELECT '?' DATABASENAME, NAME,XTYPE FROM ?..SYSOBJECTS WHERE NAME='YourSearchingObjectName'"
SELECT * FROM #TEMP
DROP TABLE #TEMP
Note : Replace "YourSearchingObjectName" with the object name which you are searching in the select query
Tuesday, May 6, 2008
How to Audit or Bypass TRIGGER Execution Using CONTEXT_INFO()
When a TRIGGER executes, it may be useful to have the TRIGGER code know which Stored Procedure caused the action that is executing the TRIGGER code. It may be that there is a need to log the entry point, or perhaps, there is conditional logic in the TRIGGER that depends upon the entry point. In this paper, two different scenarios are addressed. First, How to Track Which Stored Procedure Fired the Trigger, and Second, How to Limit a TRIGGER to Fire ONLY from Certain Stored Prodedures. This approach has been tested with SQL Server 2005 and 2008. SQL Server 2000 requires a minor modification that is presented at the end of the paper.
Check my paper in MSDN Wiki page
http://code.msdn.microsoft.com/SQLExamples/Wiki/View.aspx?title=AuditOrBypassTriggerExecution
Check my paper in MSDN Wiki page
http://code.msdn.microsoft.com/SQLExamples/Wiki/View.aspx?title=AuditOrBypassTriggerExecution
Thursday, May 1, 2008
FAQ - How to use Stored Procedure in Select Query
Very common question in T-SQL Forums
The requirement is, need to use Stored procedure output (Exec SP) in Select query or in a Join. There is a method which may not be a recommended one. You can create a LoopBack Linked server to your own server and use OPENQUERY TO extract the data by EXECUTE Stored procedure.
LoopBack Linked Server
Linked servers can be defined to point back (loop back) to the server on which they are defined. Loopback servers are most useful when testing an application that uses distributed queries on a single server network.
Eg.
SELECT *FROM OPENROWSET
('SQLOLEDB','Server=(local);TRUSTED_CONNECTION=YES;','set fmtonly off exec master.dbo.sp_who')
OR
sp_addlinkedserver @server = N'MyLink',
@srvproduct = N' ',
@provider = N'SQLNCLI',
@datasrc = N'MyServer',
@catalog = N'AdventureWorks'
Note :
@server = N'MyLink' : It can not be your Server name. It is just a name and can be anything otherthan your actual servername. IF you give your server name in this parameter you will get an error as follows
Msg 15028, Level 16, State 1, Procedure sp_MSaddserver_internal, Line 89
The server 'LHI-115' already exists.
@datasrc = N'MyServer' : This parameter value has to be your server name or IP.
@catalog =N'AdventureWorks' : This is the database in which the Stored procedure exists.
OPENQUERY to Extract data from Loopback linkeserver
Select *from openquery([YourLoopbackServerName],'exec AdventureWorks.dbo.sptest')
The requirement is, need to use Stored procedure output (Exec SP) in Select query or in a Join. There is a method which may not be a recommended one. You can create a LoopBack Linked server to your own server and use OPENQUERY TO extract the data by EXECUTE Stored procedure.
LoopBack Linked Server
Linked servers can be defined to point back (loop back) to the server on which they are defined. Loopback servers are most useful when testing an application that uses distributed queries on a single server network.
Eg.
SELECT *FROM OPENROWSET
('SQLOLEDB','Server=(local);TRUSTED_CONNECTION=YES;','set fmtonly off exec master.dbo.sp_who')
OR
sp_addlinkedserver @server = N'MyLink',
@srvproduct = N' ',
@provider = N'SQLNCLI',
@datasrc = N'MyServer',
@catalog = N'AdventureWorks'
Note :
@server = N'MyLink' : It can not be your Server name. It is just a name and can be anything otherthan your actual servername. IF you give your server name in this parameter you will get an error as follows
Msg 15028, Level 16, State 1, Procedure sp_MSaddserver_internal, Line 89
The server 'LHI-115' already exists.
@datasrc = N'MyServer' : This parameter value has to be your server name or IP.
@catalog =N'AdventureWorks' : This is the database in which the Stored procedure exists.
OPENQUERY to Extract data from Loopback linkeserver
Select *from openquery([YourLoopbackServerName],'exec AdventureWorks.dbo.sptest')
FAQ : How can we know the progress of a maintenance command using DMVs
Its very common that, when we run DBCC maintenance command we would like to know how long will it take or how much percentage the process is completed. Here we go…
Select R.Session_id,R.Command,R.Percent_complete
From
sys.dm_exec_requests R
Inner Join
Sys.dm_exec_sessions S
on S.Session_id=R.Session_ID and S.IS_User_Process=1
This process is supported for DBCC CheckDB, DBCC CheckTable, DBCC CheckFilegroup,
DBCC IndexDefrag, DBCC Shrinkfile
Select R.Session_id,R.Command,R.Percent_complete
From
sys.dm_exec_requests R
Inner Join
Sys.dm_exec_sessions S
on S.Session_id=R.Session_ID and S.IS_User_Process=1
This process is supported for DBCC CheckDB, DBCC CheckTable, DBCC CheckFilegroup,
DBCC IndexDefrag, DBCC Shrinkfile
FAQ : How to truncate and shrink Transaction Log file in SQL Server
First of all truncation of transaction log is not a recommended practice. But it is unavoidable if you have not kept proper backup policy and recovery model for your database. Its always better to know the cause and prevention for the transaction log size issue. Refer the following KB for more info
Managing the Size of the Transaction Log File
ahttp://msdn.microsoft.com/en-us/library/ms365418(SQL.100).aspx
Transaction Log Physical Architecture
http://msdn.microsoft.com/en-us/library/ms179355(SQL.100).aspx
Factors That Can Delay Log Truncation
http://msdn.microsoft.com/en-us/library/ms345414(SQL.100).aspx
Now coming to the point. If you have no space left with the drive where the Log file is kept and the size of the Transaction Log file is not manageable then its better to shrink the log.
Broadly , you have two steps here.
(a) Mark the inactive part of Trasaction log to release.
(b) Release the marked release portion of Transaction log to OS.
SQL Server 2005
-- Step 1 – Mark the inactive part of the log for release
Use YourDatabaseName
Go
Backup Log YourDatabaseName With Truncate_Only
GO
-- Step 2 - Release the marked space to OS
Declare @LogFileLogicalName sysname
select @LogFileLogicalName=Name from sys.database_files where Type=1
print @LogFileLogicalName
DBCC Shrinkfile(@LogFileLogicalName,100)
Note : If you have single log file the above mentioned script will work. IF you have multiple log file the change the script accordingly
SQl Server 2000
-- Step 1 – Mark the inactive part of the log for release
Use YourDatabaseName
Go
Backup Log YourDatabaseName With Truncate_Only
GO
-- Step 2 - Release the marked space to OS
Declare @LogFileLogicalName sysname
select @LogFileLogicalName=Name from sysfiles where filename like '%.ldf'
print @LogFileLogicalName
DBCC Shrinkfile(@LogFileLogicalName,100)
Note : If you have single log file and the extension of the log file is .LDF the above mentioned script will work. IF you have multiple log file the change the script accordingly
SQL Server 2008
In SQL Server this process have been changed. In 20008, just change the recovery model to simple and then use DBCC SHrinkfile command.
select name,recovery_model_desc from sys.databases
GO
Alter database YourDatabaseName Recovery simple
GO
Declare @LogFileLogicalName sysname
select @LogFileLogicalName=Name from sys.database_files where Type=1
print @LogFileLogicalName
DBCC Shrinkfile(@LogFileLogicalName,100)
Managing the Size of the Transaction Log File
ahttp://msdn.microsoft.com/en-us/library/ms365418(SQL.100).aspx
Transaction Log Physical Architecture
http://msdn.microsoft.com/en-us/library/ms179355(SQL.100).aspx
Factors That Can Delay Log Truncation
http://msdn.microsoft.com/en-us/library/ms345414(SQL.100).aspx
Now coming to the point. If you have no space left with the drive where the Log file is kept and the size of the Transaction Log file is not manageable then its better to shrink the log.
Broadly , you have two steps here.
(a) Mark the inactive part of Trasaction log to release.
(b) Release the marked release portion of Transaction log to OS.
SQL Server 2005
-- Step 1 – Mark the inactive part of the log for release
Use YourDatabaseName
Go
Backup Log YourDatabaseName With Truncate_Only
GO
-- Step 2 - Release the marked space to OS
Declare @LogFileLogicalName sysname
select @LogFileLogicalName=Name from sys.database_files where Type=1
print @LogFileLogicalName
DBCC Shrinkfile(@LogFileLogicalName,100)
Note : If you have single log file the above mentioned script will work. IF you have multiple log file the change the script accordingly
SQl Server 2000
-- Step 1 – Mark the inactive part of the log for release
Use YourDatabaseName
Go
Backup Log YourDatabaseName With Truncate_Only
GO
-- Step 2 - Release the marked space to OS
Declare @LogFileLogicalName sysname
select @LogFileLogicalName=Name from sysfiles where filename like '%.ldf'
print @LogFileLogicalName
DBCC Shrinkfile(@LogFileLogicalName,100)
Note : If you have single log file and the extension of the log file is .LDF the above mentioned script will work. IF you have multiple log file the change the script accordingly
SQL Server 2008
In SQL Server this process have been changed. In 20008, just change the recovery model to simple and then use DBCC SHrinkfile command.
select name,recovery_model_desc from sys.databases
GO
Alter database YourDatabaseName Recovery simple
GO
Declare @LogFileLogicalName sysname
select @LogFileLogicalName=Name from sys.database_files where Type=1
print @LogFileLogicalName
DBCC Shrinkfile(@LogFileLogicalName,100)
FAQ : How triggers in SQL Server 2005 impact Tempdb
In SQL Server 2005 the triggers are implemented using Version store feature. In earlier versions (SQL Server 2000/ SQL 7), the trigger's Inserted and Deleted tables data were captured by reading Transaction log. But in SQL Server 2005, the Inserted and Deleted data is stored in Tempdb as row version. So, if you have more trigger in SQL Server 2005, it may impact Tempdb performance.
FAQ : How to run DBCC DBREINDEX against all the user table in SQL Server
Simple, use undocumented stored procedure sp_msforeachtable. Since its undocumented there is no gurantee that it will be available in all the future versions. But in SQL Server 2000 and 2005 it works.
Use YourdatabaseName
EXEC sp_msforeachtable 'DBCC DBREINDEX( ''?'')'
Use YourdatabaseName
EXEC sp_msforeachtable 'DBCC DBREINDEX( ''?'')'
FAQ : SQL Server DBA as a career option
This is a very common question in SQL Forums hence i thought to blog my view.
If you are a college passed out or a newbie in IT field, then I would suggest you to go for SQL Server MCTS (70-431) and MCITP DBA (70-443 and 70-444) certifications. Do not clear the certification for the sake of it. Learn the techniques and best practices mentioned in the syllabus. You must also go through the Virtual Courses available in Microsoft site. One great thing about Microsoft is , there are fantastic resource available in internet which comes free of cost. You just need to have MSN Live ID and login with that ID and refer the resource. Also must not forget download all the SQL OnDemand webcasts available in Microsoft site. Mind you, Webcast comes right from very experience folks who have been working for decades in this technology and also from the product teams who developed that products. Basically, reading , listening to experience people (webcast) and learn new technology will certainly give you a good launch in SQL Server. Always try to start with new product versions available (like at this point of time we have 2005 and 2008 CTP) in the market to be a leader rather than a follower.
For those who are already into IT field and wants to switch to DBA career can also more or less follow the same steps I have mentioned earlier. Key point in DBA for that matter any field, is Documentation. Try to document day to day activities and be process oriented. DBA is very risky at the same time secure job. Contradictory statements right?. Risky because you are working on production and data is nothing less than god for a DBA or you can say Data is your job. If anything goes wrong, it will may cost your job also. Secure, because the technology in Database generally not changes drastically. Consider one is working in VB 6 and one fine day he has been told to work in .Net 2.0. He will surely have tough time. But for a DBA to jump from SQL Server 2000 to 2005 or 2008 may be a smooth drive compared to other technologies.
SQL Server 2008 Virtual Lab
http://technet.microsoft.com/en-us/cc164207.aspx
SQL Server 2005 Virtual Lab
http://technet.microsoft.com/en-us/bb499681.aspx
SQL Server 2000 Virtual Lab
http://technet.microsoft.com/en-us/bb499685.aspx
Microsoft ondemand Webcasts
http://www.microsoft.com/events/webcasts/ondemand.mspx
Information about all the certification available SQL Server 2005
http://madhuottapalam.blogspot.com/2007_10_01_archive.html
If you are a college passed out or a newbie in IT field, then I would suggest you to go for SQL Server MCTS (70-431) and MCITP DBA (70-443 and 70-444) certifications. Do not clear the certification for the sake of it. Learn the techniques and best practices mentioned in the syllabus. You must also go through the Virtual Courses available in Microsoft site. One great thing about Microsoft is , there are fantastic resource available in internet which comes free of cost. You just need to have MSN Live ID and login with that ID and refer the resource. Also must not forget download all the SQL OnDemand webcasts available in Microsoft site. Mind you, Webcast comes right from very experience folks who have been working for decades in this technology and also from the product teams who developed that products. Basically, reading , listening to experience people (webcast) and learn new technology will certainly give you a good launch in SQL Server. Always try to start with new product versions available (like at this point of time we have 2005 and 2008 CTP) in the market to be a leader rather than a follower.
For those who are already into IT field and wants to switch to DBA career can also more or less follow the same steps I have mentioned earlier. Key point in DBA for that matter any field, is Documentation. Try to document day to day activities and be process oriented. DBA is very risky at the same time secure job. Contradictory statements right?. Risky because you are working on production and data is nothing less than god for a DBA or you can say Data is your job. If anything goes wrong, it will may cost your job also. Secure, because the technology in Database generally not changes drastically. Consider one is working in VB 6 and one fine day he has been told to work in .Net 2.0. He will surely have tough time. But for a DBA to jump from SQL Server 2000 to 2005 or 2008 may be a smooth drive compared to other technologies.
SQL Server 2008 Virtual Lab
http://technet.microsoft.com/en-us/cc164207.aspx
SQL Server 2005 Virtual Lab
http://technet.microsoft.com/en-us/bb499681.aspx
SQL Server 2000 Virtual Lab
http://technet.microsoft.com/en-us/bb499685.aspx
Microsoft ondemand Webcasts
http://www.microsoft.com/events/webcasts/ondemand.mspx
Information about all the certification available SQL Server 2005
http://madhuottapalam.blogspot.com/2007_10_01_archive.html
How to find the time taken (total elapsed time) by the query?
Though SQL Server provides SET STATISTICS TIME option to find the total elapsed time taken by a query or a sp, I generally do not use this because, for large number of statement reading the output of Statistics time will be difficult. It is better to keep your own script to get the elapsed time. Here is the script
DECLARE
@total_elapsed_time VARCHAR(100),
@start_time Datetime,
@complete_time Datetime
SELECT @start_time = GETDATE()
Print @start_time
-- here Paste the query which you want to execute
select *From sysobjects ,sys.tables – Replace this query with your query /sp
Set @complete_time=getdate()
SELECT
@total_elapsed_time = 'Total Elapsed Time (minutes:seconds) ' +
CONVERT(CHAR(3),
DATEDIFF(SS,@start_time,@complete_time)/60) +
':' +
CONVERT(CHAR(3),
DATEDIFF(SS,@start_time,@complete_time)%60)
print @total_elapsed_time
Note : If you want to know how long compilation and optimization took then use SET STATISTICS TIME
DECLARE
@total_elapsed_time VARCHAR(100),
@start_time Datetime,
@complete_time Datetime
SELECT @start_time = GETDATE()
Print @start_time
-- here Paste the query which you want to execute
select *From sysobjects ,sys.tables – Replace this query with your query /sp
Set @complete_time=getdate()
SELECT
@total_elapsed_time = 'Total Elapsed Time (minutes:seconds) ' +
CONVERT(CHAR(3),
DATEDIFF(SS,@start_time,@complete_time)/60) +
':' +
CONVERT(CHAR(3),
DATEDIFF(SS,@start_time,@complete_time)%60)
print @total_elapsed_time
Note : If you want to know how long compilation and optimization took then use SET STATISTICS TIME
Sunday, April 20, 2008
FAQ: How to rename SA Account in SQL Server 2005
I never never knew that renaming SA is possible in SQL Server 2005. Recently i found a forum post and tried here we go...
ALTER LOGIN sa DISABLE;
ALTER LOGIN sa WITH NAME = [NewNameforSA];
ALTER LOGIN sa DISABLE;
ALTER LOGIN sa WITH NAME = [NewNameforSA];
Tuesday, April 15, 2008
How to export the output of a stored procedure or query to a text file using SQLCMD command in SQL Server 2005 and later versions
How to pump the output of a stored procedure or query to a text file using SQLCMD command in SQL Server 2005 and later versions
(a) Running SQLCMD command in Command prompt and create a file from the output
(b) Push the output of a query to a file using XP_CMDShell and SQLCMD command
Now what happens If we want to do this from Query Analyser. Simple , run the same command using XP_CMDShell.
(a) Open a Query Analyser in Management Studio
(b) Run the following query
Exec XP_CMDShell 'sqlcmd -Sservername -dmaster -Usa -Psa -q"select *from sys.objects" -oC:\testoutput.txt'
(c) Third and simple method
We all know the two methods mentioned above. But there is another method which is very simple and flexible. SQL Server Management Studio Query Editor has support for SQLCMD scripts authoring and execution. We can switch ON or Off this feature.
(a) Open Management Studio
(b) Tools Menu -->> Select Options Query Execution General check the check box at the bottom of the page on the right side of the dialog “By default, open new queries in SQLCMD mode.”
(c) Press OK and save the settings
(d) Now , open a query analyzer and type the following
:out c:\queryresults.txt
:error c:\queryerror.txt
GO
Select *from sys.objects
go
Select *from sys.objectsaaa
Note : In the above mentioned command the output of the first query will be pushed to C:\queryresults.txt and the error due to the second select statement will be pushed to c:\queryerror.txt
Disclaimer :
All the SQLCMD commands are not supported from Query Analyser. Following are the SQLCMD commands not supported in Query Analyser
(a):serverlist Lists local and SQL Servers on the network.
(b) :reset Discards the statement cache.
(c) :perftrace Redirects timing output to a file, stderr, or stdout. This is not supported because Query Editor doesn't have this concept.
(d) :listvar Lists the set SQLCMD scripting variables.
(e) :ed Edits the current or last executed statement cache.
(f) :help Shows the list of supported commands.
if you use any command in Query Analyser, Query Editor issues a non-fatal warning into the Messages tab during execution and continues on.
Summary :
All the three methods are equally useful. Many folks may not have observed the third method that is why i thought to blog this..
(a) Running SQLCMD command in Command prompt and create a file from the output
C:\> sqlcmd -Sservername -dmaster -Usa -Psa -q"se
lect *from sys.objects" -oC:\testoutput.txt
(b) Push the output of a query to a file using XP_CMDShell and SQLCMD command
Now what happens If we want to do this from Query Analyser. Simple , run the same command using XP_CMDShell.
(a) Open a Query Analyser in Management Studio
(b) Run the following query
Exec XP_CMDShell 'sqlcmd -Sservername -dmaster -Usa -Psa -q"select *from sys.objects" -oC:\testoutput.txt'
(c) Third and simple method
We all know the two methods mentioned above. But there is another method which is very simple and flexible. SQL Server Management Studio Query Editor has support for SQLCMD scripts authoring and execution. We can switch ON or Off this feature.
(a) Open Management Studio
(b) Tools Menu -->> Select Options Query Execution General check the check box at the bottom of the page on the right side of the dialog “By default, open new queries in SQLCMD mode.”
(c) Press OK and save the settings
(d) Now , open a query analyzer and type the following
:out c:\queryresults.txt
:error c:\queryerror.txt
GO
Select *from sys.objects
go
Select *from sys.objectsaaa
Note : In the above mentioned command the output of the first query will be pushed to C:\queryresults.txt and the error due to the second select statement will be pushed to c:\queryerror.txt
Disclaimer :
All the SQLCMD commands are not supported from Query Analyser. Following are the SQLCMD commands not supported in Query Analyser
(a):serverlist Lists local and SQL Servers on the network.
(b) :reset Discards the statement cache.
(c) :perftrace Redirects timing output to a file, stderr, or stdout. This is not supported because Query Editor doesn't have this concept.
(d) :listvar Lists the set SQLCMD scripting variables.
(e) :ed Edits the current or last executed statement cache.
(f) :help Shows the list of supported commands.
if you use any command in Query Analyser, Query Editor issues a non-fatal warning into the Messages tab during execution and continues on.
Summary :
All the three methods are equally useful. Many folks may not have observed the third method that is why i thought to blog this..
Tuesday, April 1, 2008
FAQ : How to clear SQL Server cache / memory
Warning : Not to be used in production env.
In Development or tsesting env its very common that during performance tuning we do clear cache to get correct picture. It may also required that only a particular db related cache should be clear. here wo go...
(a) Clear entire procedure and databuffer cache
Checkpoint -- Write dirty pages to disk
DBCC FreeProcCache -- Clear entire proc cache
DBCC DropCleanBuffers -- Clear entire data cache
(b) Clear only a particular db procedure cache using undocumented DBCC command
Declare @DBID int
Select @DBID =db_id(‘YourDBname’)
DBCC FLUSHPROCINDB(@DBID) – Undocumented dbcc command to clear only a db proc cache
In Development or tsesting env its very common that during performance tuning we do clear cache to get correct picture. It may also required that only a particular db related cache should be clear. here wo go...
(a) Clear entire procedure and databuffer cache
Checkpoint -- Write dirty pages to disk
DBCC FreeProcCache -- Clear entire proc cache
DBCC DropCleanBuffers -- Clear entire data cache
(b) Clear only a particular db procedure cache using undocumented DBCC command
Declare @DBID int
Select @DBID =db_id(‘YourDBname’)
DBCC FLUSHPROCINDB(@DBID) – Undocumented dbcc command to clear only a db proc cache
FAQ : How to move a physical file (MDF or LDF) from one location to another in SQL Server 2005
In SQL Server 2000, if you want to move a physical file of a database from one location to another , you have to detach and attach the database. In SQL Server 2005, this process has been made very simple, you need to take the database offline, alter the file path with the new one using Alter Database command and copy the database file to new location manually and finally take the database online. Simple
--Step 1 : Create Database
Create Database TestMoveFile and check the database file location
GO
Select *From Sys.master_files where database_id=db_id('TestmoveFile')
GO
--Step 2 : Alter Database and Set the db to offline
Alter Database TestMoveFile Set Offline
GO
-- Step 3 : Move the physical file to new location
--Move the file to new location using dos command or Windows GUI
--Step 4 : Alter the database file path using Alter Database command
Alter Database TestMoveFile Modify File(Name='TestMoveFile',FileName='c:\TestmoveFile.mdf')
Go
-- Step 5 : Set the database Online and check the file path
Alter database TestMoveFile Set Online
GO
Select *From Sys.master_files where database_id=db_id('TestmoveFile')
Go
Drop database TestMoveFile
--Step 1 : Create Database
Create Database TestMoveFile and check the database file location
GO
Select *From Sys.master_files where database_id=db_id('TestmoveFile')
GO
--Step 2 : Alter Database and Set the db to offline
Alter Database TestMoveFile Set Offline
GO
-- Step 3 : Move the physical file to new location
--Move the file to new location using dos command or Windows GUI
--Step 4 : Alter the database file path using Alter Database command
Alter Database TestMoveFile Modify File(Name='TestMoveFile',FileName='c:\TestmoveFile.mdf')
Go
-- Step 5 : Set the database Online and check the file path
Alter database TestMoveFile Set Online
GO
Select *From Sys.master_files where database_id=db_id('TestmoveFile')
Go
Drop database TestMoveFile
FAQ : What is the difference between DELETE TABLE and TRUNCATE TABLE commands
TRUNCATE
• Less Transaction Log entry because TRUNCATE TABLE removes the data by deallocating the data pages used to store the table data and records only the page deallocations in the transaction log and hence TRUNCATE is fast
• TRUNCATE apply Fewer table locks
• TRUNCATE is DDL Statement
• TRUNCATE Release the tables spaces to System
• TRUNCATE Can not have WHERE Conditions
• TRUNCATE does not fire trigger
• TRUNCATE reset the identity to 0 (if table have any)
• TRUNCATE Can not be used against the tables involved in TRUNCATE transactional replication or merge replication.
• TRUNCATE Can not be used against the table used in Indexed view
• TRUNCATE can not be used against the table that Are referenced by a FOREIGN KEY constraint.
• TRUNCATE commands are not tracked by DDL trigger
Note : TRUNCATE can be rollbacked. I have seen many place where its is mentioned that it can not
DELETE
• DELETE FROM TABLE command logs each records in transaction log , hence DELETE is slow.
• DELETE apply more locks to the table
• DELETE is a DML command
• DELETE remove the records but will not release the space to the system
• DELETE can have WHERE conditions
• DELETE Fires TRIGGER
• DELETE do not RESET IDENTITY
• DELETE Can be used against table used transactional replication or merge replication
• DELETE Can be used in tables reference by a Foregin Key and tables involved in Indexed view
• Less Transaction Log entry because TRUNCATE TABLE removes the data by deallocating the data pages used to store the table data and records only the page deallocations in the transaction log and hence TRUNCATE is fast
• TRUNCATE apply Fewer table locks
• TRUNCATE is DDL Statement
• TRUNCATE Release the tables spaces to System
• TRUNCATE Can not have WHERE Conditions
• TRUNCATE does not fire trigger
• TRUNCATE reset the identity to 0 (if table have any)
• TRUNCATE Can not be used against the tables involved in TRUNCATE transactional replication or merge replication.
• TRUNCATE Can not be used against the table used in Indexed view
• TRUNCATE can not be used against the table that Are referenced by a FOREIGN KEY constraint.
• TRUNCATE commands are not tracked by DDL trigger
Note : TRUNCATE can be rollbacked. I have seen many place where its is mentioned that it can not
DELETE
• DELETE FROM TABLE command logs each records in transaction log , hence DELETE is slow.
• DELETE apply more locks to the table
• DELETE is a DML command
• DELETE remove the records but will not release the space to the system
• DELETE can have WHERE conditions
• DELETE Fires TRIGGER
• DELETE do not RESET IDENTITY
• DELETE Can be used against table used transactional replication or merge replication
• DELETE Can be used in tables reference by a Foregin Key and tables involved in Indexed view
FAQ : Index Scan Vs Seek in SQL Server
There are five logical/physical operators in SQL Server related to Index scan ,Index Seek and Table scan.
(a) Table Scan
(b) Clustered Index Scan
(c) Clustered Index Seek
(d) Index Scan (Non- Clustered index Seek)
(e) Index Seek (Non- Clustered index Seek)
Table Scan
Table Scan retrieves all rows from the table (if you have no WHERE Conditions). Basically, before returning the rows, it traverse through all data pages related to the table. If you have where condition, though it travel through all the pages only those rows are returned which satisfy the conditions. When you do not have Clustered index on the table it does a table scan. In other words, both Clustered Index Scan (clustered index is nothing but the data itself) and Table Scan are same because in both method system traverse through all the data pages. Generally, you should avoid table scan.
Clustered Index Scan
Clustered Index Scan is nothing but horizontally traversing though the clustered index data pages. Clustered Index Scan return all the rows from the clustered index (Clustered index is nothing but Data). If you have where condition , only the satisfying rows are returned, but system traverse through all the data pages of the clustered index. Both Table scan and Clustered Index Scan are generally considered to be bad. But at times like if the table is small contains only few rows table or clustered index scan may be good also
Clustered Index Seek
Clustered Index Seek traverse vertically right down to the Data page where the requested data is stored. Basically any seek is vertically traversing though the B-Tree structure (as we all know the index is stored in B-tree structure in sql server). System does a Seek when it find a useful index and generally its done for highly selective query.
Index Scan or Non-Clustered Index Scan
As already said, Scan is horizontal traversing of B-Tree data pages. But in this case it horizontally traverse though the Non-Clustered index available. Its not same as Clustered index scan or Table Scan. In SQL Server , while reading execution plan you can find only Index Scan not Non-Clustered Index Scan. But you must read Index Scan as Non-Clustered Index Scan.
Index Seek or Non-Clustered Index Seek
As already mentioned Seek is Vertical traversing of B-Tree to the data page. But in Index seek it vertical traversing of Non-Clustered Index. Generally, its considered as the best option for high selective query.
(a) Table Scan
(b) Clustered Index Scan
(c) Clustered Index Seek
(d) Index Scan (Non- Clustered index Seek)
(e) Index Seek (Non- Clustered index Seek)
Table Scan
Table Scan retrieves all rows from the table (if you have no WHERE Conditions). Basically, before returning the rows, it traverse through all data pages related to the table. If you have where condition, though it travel through all the pages only those rows are returned which satisfy the conditions. When you do not have Clustered index on the table it does a table scan. In other words, both Clustered Index Scan (clustered index is nothing but the data itself) and Table Scan are same because in both method system traverse through all the data pages. Generally, you should avoid table scan.
Clustered Index Scan
Clustered Index Scan is nothing but horizontally traversing though the clustered index data pages. Clustered Index Scan return all the rows from the clustered index (Clustered index is nothing but Data). If you have where condition , only the satisfying rows are returned, but system traverse through all the data pages of the clustered index. Both Table scan and Clustered Index Scan are generally considered to be bad. But at times like if the table is small contains only few rows table or clustered index scan may be good also
Clustered Index Seek
Clustered Index Seek traverse vertically right down to the Data page where the requested data is stored. Basically any seek is vertically traversing though the B-Tree structure (as we all know the index is stored in B-tree structure in sql server). System does a Seek when it find a useful index and generally its done for highly selective query.
Index Scan or Non-Clustered Index Scan
As already said, Scan is horizontal traversing of B-Tree data pages. But in this case it horizontally traverse though the Non-Clustered index available. Its not same as Clustered index scan or Table Scan. In SQL Server , while reading execution plan you can find only Index Scan not Non-Clustered Index Scan. But you must read Index Scan as Non-Clustered Index Scan.
Index Seek or Non-Clustered Index Seek
As already mentioned Seek is Vertical traversing of B-Tree to the data page. But in Index seek it vertical traversing of Non-Clustered Index. Generally, its considered as the best option for high selective query.
Tuesday, February 26, 2008
FAQ : Query to get all the Dynamic Management Views/Functions
Select * From Sys.All_Objects
Where Type IN ('V','TF','IF')
and Name Like '%dm_%' And
Schema_ID=4
Where Type IN ('V','TF','IF')
and Name Like '%dm_%' And
Schema_ID=4
Thursday, February 7, 2008
Webcasts in Feb 2008
Check out the webcasts schedule in the month of Feb.
http://www.microsoft.com/india/webcasts/
http://www.microsoft.com/india/webcasts/
Saturday, February 2, 2008
DOs and Don’t when Running Profiler
We run profiler often for many reasons. We generally, do this on Test/UAT environment. Running profiler on production is not recommended but not completely avoidable always. You may need to run profiler/trace even on production server. But to get better result with less overload, we may need to follow some guideline. I think following are the general guideline which we can follow when we run profiler on any environment.
(a) Do not save the trace result into a table on the same database
(b) Run the trace with proper filter. Monitor only the required events otherwise the trace may overload the system.
(c) Run the trace from any other machines other than which you are monitoring. You can connect from Test server or any other workstation which acts as a monitor to the actual server.
(d) If you are running the trace for workload then run the Trace for the whole business day when activities are high to get exact picture.
(e) Create a template with the events you need and save it to re-use.
(f) You may save the result to a table so that you can run sql query against it.
Note : It is always recommended to run T-SQL Storedprocedure that define the trace rather than running Profiler GUI.
(a) Do not save the trace result into a table on the same database
(b) Run the trace with proper filter. Monitor only the required events otherwise the trace may overload the system.
(c) Run the trace from any other machines other than which you are monitoring. You can connect from Test server or any other workstation which acts as a monitor to the actual server.
(d) If you are running the trace for workload then run the Trace for the whole business day when activities are high to get exact picture.
(e) Create a template with the events you need and save it to re-use.
(f) You may save the result to a table so that you can run sql query against it.
Note : It is always recommended to run T-SQL Storedprocedure that define the trace rather than running Profiler GUI.
Tuesday, January 1, 2008
A dream come true... you can call me MVP
I have no words... I have been honoured by Microsoft and I am a MVP now... From a Soldier to a MVP, probably first MVP from Indian Defence Services , its been a great new year for me
Subscribe to:
Posts (Atom)



